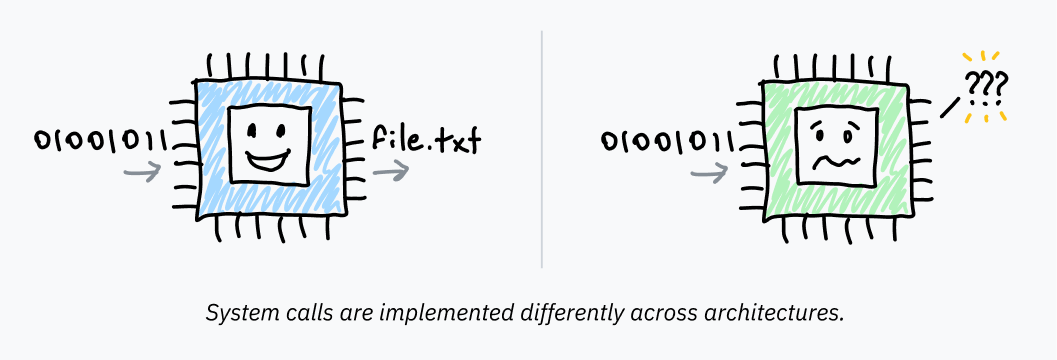
Chapter 0: イントロ
私はコンピュータでたくさんのことをしてきましたが、私の知識には常にギャップがありました:コンピュータでプログラムを実行するときに実際に何が起こるのか? このギャップについて考えました - 必要な低レベルの知識のほとんどは持っていましたが、すべてを組み合わせるのに苦労していました。プログラムは本当にCPU上で直接実行されているのでしょうか、それとも何か別のことが起こっているのでしょうか? syscallsを使用したことはありますが、それらは実際にはどのように動作するのでしょうか? それらは本当に何なのでしょうか? 複数のプログラムはどのように同時に実行されるのでしょうか?
私は我慢できず、できる限り多くのことを勉強しはじめました。大学に行っていない場合、包括的なシステムリソースはあまりありませんので、いろいろな質のさまざまなソースを大量に調査し、時には矛盾する情報をふるいにかける必要がありました。数週間の研究とほぼ40ページに及ぶノートの後、コンピュータが起動してプログラムが実行されるまでの仕組みをはるかによく理解できるようになったと思います。私は自分が学んだことを説明するための一つの確かな記事があれば最高だと思っていたので、自分が欲しかった記事を書いています。
そして、よく言われるように「誰かに説明できるようになってはじめて、物事を理解したといえる」のでね。
急いでいますか? すでにこれらのことを知っている気がしますか?
第3章を読むと、新しいことを学べると保証します。あなたがLinus Torvaldsでない限り。
Chapter 1: 基礎
この記事を書きながら何度も驚いたことの1つは、コンピューターがどれほどシンプルであるかでした。私はまだ、「現実以上の複雑さや抽象性を求めるな」と自分自身を説得するのが難しいくらいです!続ける前に、頭に焼き付けるべきことが1つあるなら、それはすべてが見かけの通りに実際に単純であるということです。この単純さは非常に美しく、時には非常に、非常に呪われていることがあります。
さて、あなたのコンピューターがその最も基本的な部分でどのように動作するかの基本から始めましょう。
コンピューターアーキテクチャの仕組み
コンピューターの中央処理装置(CPU)は、すべての計算を担当しています。それが全ての指示を実行する主要な部分です。それはまさに大役を果たします。それは魔法のようなものです。コンピューターを起動するとすぐに作動し、指示を次々に実行します。
最初の量産型CPUは、イタリアの物理学者でエンジニアであるFederico Fagginによって1960年代末に設計されたインテル4004でした。それは現代の64ビットシステムとは異なり、はるかに単純でしたが、その単純さの多くは今でも残っています。
CPUが実行する「指示」は、単なるバイナリデータです。実行されている指示を表すための1バイトまたは2バイト(オペコード)の後に、指示を実行するために必要なデータが続きます。私たちが機械語と呼ぶものは、実際にはこれらのバイナリ指示の連続です。アセンブリ言語は、生のビットよりも読み書きしやすい、人間が読み書きするのに役立つ構文です。それは常に、CPUが読み取る方法を知っているバイナリにコンパイルされます。

注:命令は常に上記の例のように機械語で1:1で表されるわけではありません。例えば、
add eax, 512は05 00 02 00 00に翻訳されます。最初のバイト(
05)は、EAXレジスタに32ビットの数値を加算することを特定するオペコードです。残りのバイトは 512 (0x200) で、リトルエンディアン バイト順序です。Defuse Securityは、アセンブリと機械語の変換を試すための便利なツールを作成しました。
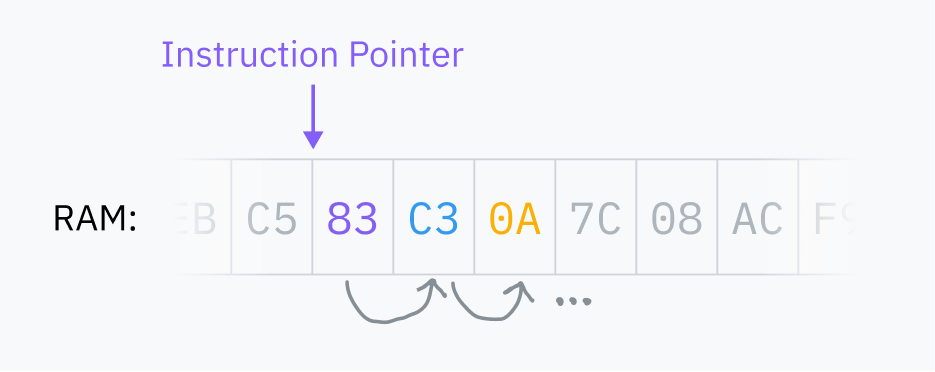
RAMはコンピュータの主記憶バンクであり、コンピュータ上で実行されるプログラムが使用するすべてのデータを格納する大きな汎用スペースです。これにはプログラムコード自体と、オペレーティングシステムのコアにあるコードも含まれます。CPUは常に機械語をRAMから直接読み取り、RAMにロードされていない場合はコードを実行できません。
CPUは 命令ポインタ を保持し、RAM内の次の命令を取得する場所を指します。各命令を実行した後、CPUはポインタを移動させて繰り返します。これが フェッチ実行サイクル です。
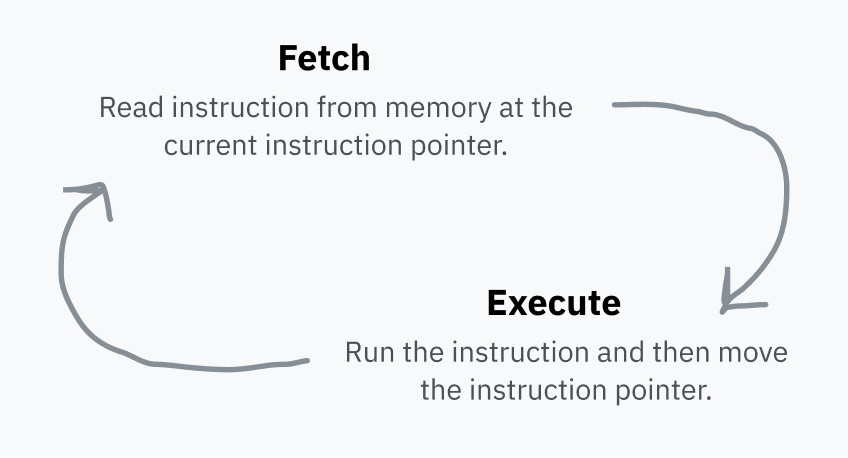
命令を実行した後、ポインターはRAM内のその命令の直後に移動します。これにより、ポインターは次の命令を指すようになります。これがコードが実行される理由です!命令ポインターは単純に前に進み続け、メモリに格納された順序で機械語を実行します。一部の命令は、代わりに命令ポインターを他の場所にジャンプさせるか、特定の条件に応じて異なる場所にジャンプさせることができます。これにより、再利用可能なコードと条件付きロジックが可能になります。
この命令ポインターはレジスタに格納されています。レジスタはCPUが読み書きするのが非常に速い小さなストレージバケットです。各CPUアーキテクチャには、計算中に一時的な値を保存するためからプロセッサを設定するためまで、固定のレジスタセットがあります。
一部のレジスタは機械語から直接アクセスできるもので、先の図では ebx がその例です。
他のレジスタはCPU内部でのみ使用されますが、特殊な命令を使用して更新または読み取ることができることがあります。その一例が命令ポインターであり、直接読み取ることはできませんが、例えばジャンプ命令を使用して更新できます。
プロセッサは単純です
最初に、実行可能プログラムをコンピュータ上で実行すると何が起こるかについて考えてみましょう。まず、それを実行する準備のために多くの魔法が行われます — これについては後で詳しく説明します — しかし、プロセスの最後にはどこかのファイルに機械語があります。オペレーティングシステムはこれをRAMに読み込み、CPUに指示して命令ポインタをRAM内のその位置にジャンプさせます。CPUは通常通りフェッチ-実行サイクルを実行し続けるため、プログラムは実行を開始します!
(これは私にとって、本当に、この記事を読んでいるために使用しているプログラムがどのように動作しているかという瞬間の1つでした!あなたのCPUは、RAMからブラウザの命令を順番にフェッチし、それらを直接実行して、この記事を表示しています。)
実は、CPUは非常に基本的な世界観を持っています。CPUは現在の命令ポインタと少量の内部状態しか見ることができません。プロセスは完全にオペレーティングシステムの抽象概念であり、CPUが元々理解または追跡しているものではありません。
*手を振る* プロセスは、コンピュータをもっと売るためにos devs大きなバイトによって作成された抽象概念です
私にとって、これはより多くの疑問を呼び起こします:
- CPUはマルチプロセッシングについて知らないし、命令を順次実行するだけなので、実行中のプログラム内で詰まらないのはなぜですか?複数のプログラムはどのように同時に実行できるのでしょうか?
- プログラムはCPU上で直接実行され、CPUはRAMに直接アクセスできるので、なぜコードは他のプロセスまたはカーネルからメモリにアクセスできないのでしょうか?
- 言ってみれば、すべてのプロセスがコンピュータに対してどんな命令も実行し、何でもできないようにするメカニズムは何ですか?それにしても、シスコール(システムコール)って何ですか?
メモリに関する質問は独自のセクションが必要であり、第5章 で取り上げられていますが、要約すると、ほとんどのメモリアクセスは実際にはアドレス空間全体をリマップする誤誘導の層を通過します。今のところ、プログラムはすべてのRAMに直接アクセスでき、コンピュータは一度に1つのプロセスしか実行できないと仮定しましょう。これらの仮定の両方を後で説明します。
さあ、最初のウサギの穴に飛び込んで、シスコールとセキュリティリングが詰まった世界に入りましょう。
余談:ところで、カーネルって何ですか?
あなたのコンピュータのオペレーティングシステム、たとえばmacOS、Windows、またはLinuxは、コンピュータ上で動作し、すべての基本的な機能を実現するソフトウェアの集まりです。 “基本的な機能” とは非常に一般的な用語であり、同様に “オペレーティングシステム” もそうです。異なる人に尋ねると、それにはコンピュータにデフォルトで付属するアプリ、フォント、アイコンなども含まれるかもしれません。
しかし、カーネルはオペレーティングシステムの中核です。コンピュータを起動すると、命令ポインタはどこかのプログラムから開始します。そのプログラムがカーネルです。カーネルはコンピュータのメモリ、周辺機器、その他のリソースにほぼ完全なアクセス権を持ち、コンピュータにインストールされたソフトウェア(ユーザーランドプログラムと呼ばれるもの)を実行する責任があります。この記事の途中で、カーネルがこのアクセス権を持つ方法と、ユーザーランドプログラムが持たない方法について学びます。
Linuxはカーネルだけであり、シェルやディスプレイサーバなどのユーザーランドソフトウェアが必要です。macOSのカーネルはXNUと呼ばれ、Unixのようです。また、現代のWindowsカーネルはNTカーネルと呼ばれています。
二つのリングで彼らを支配せよ
モード(時折特権レベルまたはリングと呼ばれることもあります)は、プロセッサが許可されていることを制御します。現代のアーキテクチャには、少なくともカーネル/スーパーバイザーモードとユーザーモードの2つのオプションがあります。アーキテクチャが2つ以上のモードをサポートするかもしれませんが、これらの日常的に使用されるのはカーネルモードとユーザーモードだけです。
カーネルモードでは、何でも可能です。CPUはサポートされているすべての命令を実行し、すべてのメモリにアクセスすることが許可されています。ユーザーモードでは、一部の命令のみが許可され、I/Oおよびメモリアクセスが制限され、多くのCPU設定がロックされます。一般的に、カーネルとドライバはカーネルモードで実行され、アプリケーションはユーザーモードで実行されます。
プロセッサはカーネルモードで起動します。プログラムを実行する前に、カーネルはユーザーモードへの切り替えを開始します。

プロセッサモードが実際のアーキテクチャでどのように表れるかの例:x86-64アーキテクチャでは、現在の特権レベル(CPL)はcs(コードセグメント)と呼ばれるレジスタから読み取ることができます。具体的には、CPLはcsレジスタの2つの最下位ビットに含まれています。これらの2つのビットはx86-64の4つの可能なリングを格納できます:リング0はカーネルモードであり、リング3はユーザーモードです。リング1とリング2はドライバを実行するために設計されていますが、ほんの一部の古いニッチなオペレーティングシステムでしか使用されていません。たとえばCPLビットが11であれば、CPUはリング3、つまりユーザーモードで実行されています。
シスコールとは一体何なのでしょうか?
プログラムは、コンピュータへの完全なアクセス権を持つことができないため、ユーザーモードで実行されます。ユーザーモードは、コンピュータのほとんどへのアクセスを制限し、しかし、プログラムは何らかの方法でI/Oへのアクセス、メモリの割り当て、そしてオペレーティングシステムとの対話ができる必要があります!これを実現するために、ユーザーモードで実行されるソフトウェアは、オペレーティングシステムカーネルに助けを求める必要があります。オペレーティングシステムは、プログラムが悪意のある操作を行わないように独自のセキュリティ保護を実装できます。
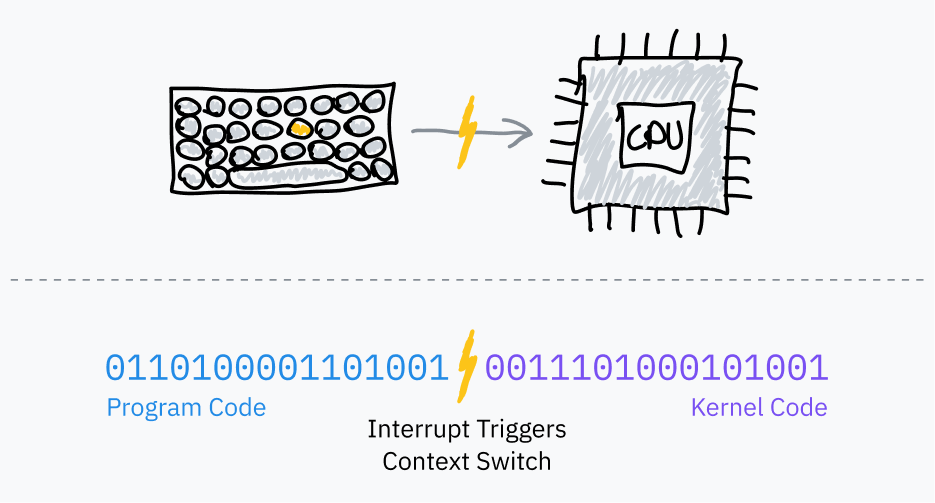
もしもオペレーティングシステムと対話するコードを書いたことがあれば、おそらく open、read、fork、exit などの関数を認識するでしょう。これらの関数は、抽象化のいくつか下に、オペレーティングシステムに助けを求めるために システムコール を使用しています。システムコールは、プログラムがユーザースペースからカーネルスペースへの移行を開始し、プログラムのコードからOSのコードにジャンプさせる特別な手続きです。
ユーザースペースからカーネルスペースへの制御移行は、ソフトウェア割り込み と呼ばれるプロセッサ機能を使用して実現されます:
- ブートプロセス中、オペレーティングシステムはRAMに 割り込みベクターテーブル (IVT; x86-64ではこれを 割り込みディスクリプタテーブル と呼びます) という表を格納し、CPUに登録します。IVTは割り込み番号をハンドラコードポインタにマッピングします。

- それから、ユーザーランドのプログラムは INT などの命令を使用して、プロセッサに指定された割り込み番号をIVTで検索し、カーネルモードに切り替え、次にIVTに格納されたメモリアドレスに命令ポインタをジャンプさせるように指示します。
このカーネルコードが終了すると、IRET のような命令を使用して、CPUにユーザーモードに切り替え、割り込みがトリガーされたときの命令ポインタを元に戻します。
(もしも興味があれば、Linuxのシステムコールに使用される割り込みIDは 0x80 です。Linuxのシステムコールのリストは Michael Kerriskのオンラインマンページディレクトリ で読むことができます。)
Wrapper APIs: 割り込みを抽象化する
これまでのところ、システムコールについて知っていることは以下の通りです:
- ユーザーモードのプログラムは、I/Oやメモリに直接アクセスできません。外部との対話に関しては、OSに助けを求める必要があります。
- プログラムは、INTやIRETのような特別な機械語命令を使用して、OSに制御を委譲できます。
- プログラムは特権レベルを直接切り替えることはできません。ソフトウェア割り込みは安全です。なぜなら、プロセッサはOSによって事前に設定され、どのOSコードにジャンプするかが決まっています。割り込みベクターテーブルはカーネルモードからのみ設定できます。
プログラムは、システムコールをトリガーする際にオペレーティングシステムにデータを渡す必要があります。OSは、実行する特定のシステムコールと、たとえば開くファイル名のようなシステムコール自体が必要とするデータを知る必要があります。このデータの渡し方は、オペレーティングシステムとアーキテクチャによって異なりますが、通常は割り込みをトリガーする前に、特定のレジスタやスタックにデータを配置することで行われます。
デバイスごとにシステムコールの呼び出し方法が異なるため、プログラマがすべてのプログラムに対して自分でシステムコールを実装することは非常に非現実的です。これはまた、古いシステムを使用するように書かれたすべてのプログラムを壊すことを恐れてオペレーティングシステムが割り込み処理を変更できなくなることを意味します。最後に、通常、プログラムを生アセンブリで書かなくても済みます。プログラマはファイルを読み取るかメモリを割り当てるたびにアセンブリに戻ることを期待されるべきではありません。
したがって、オペレーティングシステムはこれらの割り込みの上に抽象化レイヤーを提供します。Unix系のシステムでは、libc が必要なアセンブリ命令をラップする再利用可能なハイレベルライブラリ関数を提供し、Windowsではntdll.dll と呼ばれるライブラリの一部がそれを提供します。これらのライブラリ関数を呼び出すと、カーネルモードへの切り替えは発生しません。それらは通常の関数呼び出しです。ライブラリ内部では、アセンブリコードが実際に制御をカーネルに移し、ラップされたライブラリサブルーチンよりもプラットフォーム依存性が高いです。
Unix系システム上でCから exit(1) を呼び出すと、この関数は内部でマシンコードを実行して割り込みをトリガーし、正しいレジスタ/スタック/その他の場所にシステムコールのオペコードと引数を配置します。コンピュータは本当に素晴らしいですね!
速さの必要性 / CISCの世界へ
多くのCISCアーキテクチャ、例えばx86-64は、システムコールの一般的な利用から生まれた命令を含んでいます。
インテルとAMDはx86-64に関しては非常に協力しきれておらず、実際には最適化されたシステムコール命令が2つも存在しています。SYSCALL と SYSENTER は、INT 0x80のような命令に代わる最適化された選択肢です。それらの対応するリターン命令、SYSRET と SYSEXIT は、素早くユーザースペースに戻り、プログラムコードを再開するために設計されています。
(AMDとインテルプロセッサは、これらの命令とわずかに異なる互換性を持っています。一般的に、64ビットプログラムにはSYSCALLが最適なオプションですが、32ビットプログラムとの互換性にはSYSENTERがより適しています。)
RISCアーキテクチャの代表的な特徴として、特別な命令を持たないことがあります。RISCアーキテクチャであるApple SiliconがベースとしているAArch64は、シスコールとソフトウェア割り込みの両方に対して1つの割り込み命令のみを使用します。おそらく、Macユーザーは問題なく使用していることでしょう :)
うーん、それはたくさんの情報でしたね!簡単に振り返りましょう:
- プロセッサは無限のフェッチ-実行ループで命令を実行し、オペレーティングシステムやプログラムの概念を持っておらず、通常はレジスタに保存されるモードが実行できる命令を決定します。オペレーティングシステムのコードはカーネルモードで実行され、プログラムを実行するためにユーザーモードに切り替えます。
- バイナリを実行するために、オペレーティングシステムはユーザーモードに切り替え、プロセッサをコードのRAM内のエントリーポイントに向けます。彼らはユーザーモードの特権しか持っていないため、世界とやり取りしたいプログラムはOSコードに助けを求める必要があります。システムコールは、プログラムがユーザーモードからカーネルモードに切り替えてOSコードに移行する標準化された方法です。
- プログラムは通常、これらのシステムコールを共有ライブラリ関数を呼び出すことで使用します。これらはソフトウェア割り込みまたはアーキテクチャ固有のシステムコール命令のいずれかの機械語をラップし、制御をOSカーネルに転送してリングを切り替えます。カーネルは自身の処理を行い、ユーザーモードに切り替えてプログラムコードに戻ります。
では、以前の最初の質問に答える方法を考えましょう:
CPUは複数のプロセスを追跡せず、ただ命令を実行し続けるのなら、実行中のプログラム内で固まらないのはなぜですか?複数のプログラムが同時に実行される仕組みはどのようになっていますか?
この質問への答えは、私の親愛なる友人よ、Coldplayがなぜ人気なのかという質問と同じ答えです… clocks!(厳密にはタイマーです。ただ、そのジョークをはさんでみたかっただけです。)
Chapter 2: 時間をスライス
仮にあなたがオペレーティングシステムを構築しており、ユーザーが複数のプログラムを同時に実行できるようにしたいとしましょう。ただし、ファンシーなマルチコアプロセッサは持っていないため、CPUは一度に1つの命令しか実行できません!
幸いなことに、あなたは非常に賢いOS開発者です。プロセスにCPUを交代させることで、並行処理を模倣できることを理解します。プロセスを順番に切り替えて、各プロセスからいくつかの命令を実行すれば、CPUを占有するプロセスがなくても、すべてのプロセスが応答性を持つことができます。
しかし、プログラムコードから制御を取り戻すにはどうすればいいのでしょうか?少しの調査の後、ほとんどのコンピュータにはタイマーチップが付属していることがわかります。タイマーチップをプログラムして、一定の時間が経過した後にOSの割り込みハンドラに切り替えるようにすることができます。
ハードウェア割り込み
以前、ソフトウェア割り込みがユーザーランドプログラムからOSへの制御を渡す方法についてお話ししました。これらは「ソフトウェア」割り込みと呼ばれます。プログラムによって自発的にトリガーされるためです。プロセッサによって実行される機械コードは通常のフェッチ-実行サイクルで、カーネルに制御を切り替えるように指示します。
OSのスケジューラは、PIT(Programmable Interval Timer)などの タイマーチップ を使用して、マルチタスキングのためのハードウェア割り込みをトリガーします:
- プログラムコードにジャンプする前に、OSはタイマーチップを設定して、一定時間後に割り込みをトリガーするようにします。
- OSはユーザーモードに切り替え、プログラムの次の命令にジャンプします。
- タイマーが経過すると、カーネルモードに切り替え、OSコードにジャンプする割り込みがトリガーされます。
- OSは今、プログラムが中断した場所を保存し、異なるプログラムをロードしてプロセスを繰り返すことができます。
これは 優先的なマルチタスキング と呼ばれ、プロセスの中断は 優先度変更(preemption) と呼ばれます。たとえば、ブラウザでこの記事を読んでいて、同じコンピュータで音楽を聴いている場合、あなたのコンピュータはおそらく1秒間に何千回もこの正確なサイクルを実行しています。
タイムスライス計算
タイムスライス は、OSのスケジューラがプロセスを中断する前に実行を許可する期間です。タイムスライスを選ぶもっとも簡単な方法は、すべてのプロセスに同じタイムスライスを与え、おそらく10ミリ秒程度の範囲で、タスクを順番にサイクルさせることです。これは 固定タイムスライス・ラウンドロビン スケジューリングと呼ばれます。
余談: 面白い専門用語の事実!
タイムスライスはしばしば “クォンタム” と呼ばれることがあります。これを知っていたら、テック仲間たちに感心されるでしょう。この記事の中でクォンタムを他の文で何度も言わなかったことに対して、私はたくさんの称賛を受けるべきだと思います。
タイムスライスの専門用語に関して言えば、Linuxカーネル開発者は jiffy 時間単位を使用して固定周波数のタイマータイク数をカウントします。ジフィは、タイムスライスの長さを測定するために使用されます。Linuxのジフィ周波数は通常、1000 Hzですが、カーネルをコンパイルする際に設定することができます。
固定タイムスライススケジューリングへのわずかな改善策は、ターゲットレイテンシー を選択することです — プロセスが応答するための理想的な最長時間です。ターゲットレイテンシーは、プロセスが中断された後に実行を再開するまでの時間であり、合理的な数のプロセスを想定しています。これはかなり視覚化が難しいです!心配しないでください、すぐにダイアグラムが登場します。
タイムスライスは、ターゲットレイテンシーをタスクの総数で割ることで計算されます。これは、より少ないプロセスで無駄なタスク切り替えを排除するために固定タイムスライススケジューリングよりも優れています。ターゲットレイテンシーが15ミリ秒でプロセスが10個ある場合、各プロセスには15/10または1.5ミリ秒のタイムスライスが与えられます。プロセスが3つしかない場合でも、各プロセスは目標のレイテンシーを達成しながら、5ミリ秒のより長いタイムスライスを取得します。
プロセスの切り替えは計算上の負荷が高いです。なぜなら、現在のプログラムの完全な状態を保存し、異なるプログラムを復元する必要があるからです。ある一定のポイントを過ぎると、タイムスライスが小さすぎるとプロセスの切り替えが過度に頻繁に発生し、パフォーマンスの問題が発生する可能性があります。通常、タイムスライスの長さに下限(最小の粒度)を設けることが一般的です。これは、最小の粒度が効果を発揮するプロセスの数がある場合、ターゲットレイテンシーが超えられることを意味します。
この記事を執筆時点では、Linuxのスケジューラはターゲットレイテンシーを6ミリ秒、最小の粒度を0.75ミリ秒で使用しています。
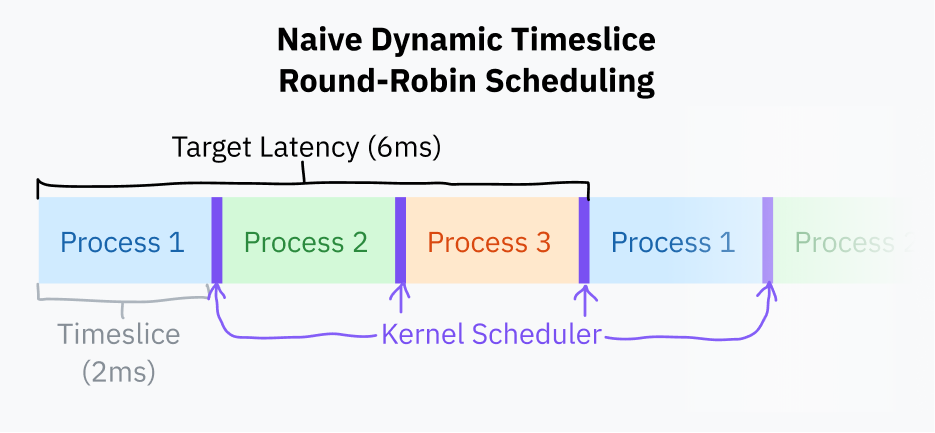
この基本的なタイムスライス計算を用いたラウンドロビンスケジューリングは、現代のほとんどのコンピュータが行うことに近いです。それでも、これは少し単純な方法です。ほとんどのオペレーティングシステムは、プロセスの優先順位や締切を考慮に入れるより複雑なスケジューラを持つ傾向があります。2007年以来、Linuxは 完全に公平なスケジューラ と呼ばれるスケジューラを使用しています。CFSはタスクを優先順位付けし、CPU時間を分配するために非常に高度なコンピュータサイエンスのテクニックを使用します。
OSがプロセスを中断するたびに、新しいプログラムの保存された実行コンテキスト、メモリ環境を読み込む必要があります。これはCPUに異なる ページテーブル、つまり “仮想” から物理アドレスへのマッピングを使用するように指示することで実現されます。これはまた、プログラムが互いのメモリにアクセスできないようにするシステムでもあります。この記事の第5章 と第6章 でこのテーマについて詳しく掘り下げていきます。
ノート #1: カーネルの優先度設定
これまで、ユーザーランドプロセスの優先度とスケジューリングについてしか話していませんでした。カーネルコードがシスコールを処理するのに時間がかかるか、ドライバーコードを実行するのに時間がかかりすぎる場合、プログラムは遅く感じることがあります。
Linuxを含む現代のカーネルは、プリエンプティブカーネル として知られています。これは、カーネルコード自体もユーザーランドプロセスと同様に中断され、スケジュールされるようにプログラムされていることを意味します。
これはカーネルを書いている場合を除いてはあまり重要ではありませんが、基本的には私が読んだ記事には必ず言及されているので、私も言及してみました!余分な知識はほとんど悪いことではありません。
ノート #2: 歴史の教訓
古代のオペレーティングシステム、クラシックなMac OSやNT以前のWindowsのバージョンなどは、プリエンプティブマルチタスキングの前身を使用していました。OSがプログラムを優先的に中断するタイミングを決定するのではなく、プログラム自体がOSに譲歩することを選択しました。彼らはソフトウェア割り込みをトリガーして、「ねえ、別のプログラムを実行させてもいいよ」と伝えました。これらの明示的な譲歩が、OSが制御を取り戻し、次にスケジュールされたプロセスに切り替える唯一の方法でした。
これは 協力的マルチタスキング と呼ばれています。これにはいくつかの重大な欠点があります:悪意のあるか、単に設計が不良なプログラムは、オペレーティングシステム全体を簡単に凍結させることができ、リアルタイム/時間に敏感なタスクの時間的整合性を確保することはほぼ不可能です。これらの理由から、テックワールドはずっと前にプリエンプティブマルチタスキングに切り替え、一度も戻ることはありませんでした。
Chapter 3: プログラムを実行する方法
これまで、CPUが実行可能ファイルから読み込まれたマシンコードを実行する方法、リングベースのセキュリティについて、およびシスコールの動作について説明しました。このセクションでは、最初にプログラムがどのように読み込まれて実行されるかを理解するために、Linuxカーネルの詳細について掘り下げて説明します。
具体的には、Linuxをx86-64で見ていきます。なぜなら?
- Linuxはデスクトップ、モバイル、およびサーバーのユースケース向けに完全な機能を備えたプロダクションOSです。Linuxはオープンソースなので、ソースコードを読むだけで簡単に調査できます。この記事ではカーネルコードを直接参照します!
- x86-64は、ほとんどの現代のデスクトップコンピュータが使用するアーキテクチャであり、多くのコードのターゲットアーキテクチャでもあります。私が言及するx86-64固有の動作のサブセットは、一般的に適用されます。
学んだことのほとんどは、特定の方法で異なる場合でも、他のオペレーティングシステムとアーキテクチャにも一般的に適用されます。
execシスコールの基本動作
非常に重要なシステムコールである「execve」から始めましょう。これはプログラムを読み込み、成功した場合には現在のプロセスをそのプログラムで置き換えます。他にもいくつかのシスコール(「execlp」、「execvpe」など)が存在しますが、それらはすべてさまざまな方法で「execve」の上に重ねています。
傍注:
execveat実際には、「execve」は「execveat」の上に構築されており、プログラムをいくつかの構成オプションで実行するより一般的なシスコールです。簡単に説明すると、主に「execve」について話します。唯一の違いは、「execveat」にいくつかのデフォルトが提供されることです。
「ve」の「ve」は、1つのパラメータが引数(
argv)のベクトル(リスト)であることを意味し、「e」はもう1つのパラメータが環境変数(envp)のベクトルであることを意味します。さまざまな他のexecシスコールには、異なる呼び出し署名を指定するための異なる接尾辞があります。「execveat」の「at」は、実行する場所を指定するものです。
execveの呼び出しシグネチャは次の通りです:
int execve(const char *filename, char *const argv[], char *const envp[]);filename引数は、実行するプログラムへのパスを指定します。argvは、プログラムへの引数のリストで、ヌル終端(最後の項目がヌルポインタであることを意味します)。Cのmain関数によく渡されるargc引数は、実際にはシスコールによって後で計算されるため、ヌル終端が必要です。envp引数には、アプリケーションのコンテキストとして使用される環境変数のヌル終端リストが含まれています。通常、これらはKEY=VALUEのペアです。 通常 です。コンピューターが大好きです。
面白い事実!プログラムの最初の引数がプログラムの名前であるという慣習、それは純粋に慣習 であり、実際にはexecveシスコール自体によって設定されていないのです!最初の引数は、argv引数の最初の項目としてexecveに渡されたものです。たとえそれがプログラム名とは何の関係もない場合でもです。
興味深いことに、execveにはargv[0]がプログラム名であると想定しているコードがいくつかあります。解釈型スクリプト言語について話す際に詳しく説明します。
ステップ 0: 定義
システムコールがどのように動作するかはすでに知っていますが、実際のコード例を見たことはありません! Linuxカーネルのソースコードを見て、execveが内部でどのように定義されているかを見てみましょう:
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}SYSCALL_DEFINE3は、3つの引数を持つシステムコールのコードを定義するためのマクロです。
マクロ名にアリティ(arity)がハードコードされている理由について興味を持ち、検索してみたところ、これはあるセキュリティの脆弱性を修正するための回避策であることが分かりました。
ファイル名の引数は、getname()関数に渡され、この関数はユーザースペースからカーネルスペースに文字列をコピーし、いくつかの使用状況トラッキング処理を行います。それはinclude/linux/fs.hで定義されているfilename構造体を返します。これはユーザースペースの元の文字列へのポインタと、カーネルスペースにコピーされた値への新しいポインタを保存します。
struct filename {
const char *name; /* pointer to actual string */
const __user char *uptr; /* original userland pointer */
int refcnt;
struct audit_names *aname;
const char iname[];
};execve システムコールは、do_execve() 関数を呼び出します。これに続いて、一部のデフォルトを持つ do_execveat_common() が呼び出されます。前述の execveat システムコールもまた do_execveat_common() を呼び出しますが、より多くのユーザー指定オプションを通過させます。
以下のスニペットでは、do_execve と do_execveat の定義を両方含めています:
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
static int do_execveat(int fd, struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp,
int flags)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(fd, filename, argv, envp, flags);
}[spacing sic]
execveatにおいて、ファイルディスクリプタ(ある種のリソースを指すIDの一種)がシスコールに渡され、それからdo_execveat_commonに渡されます。これにより、プログラムを実行するディレクトリが相対的に指定されます。
execveにおいて、ファイルディスクリプタの引数として特別な値、AT_FDCWDが使用されます。これはLinuxカーネル内の共有定数で、関数にパス名を現在の作業ディレクトリを基準として解釈するよう指示します。通常、ファイルディスクリプタを受け入れる関数は、以下のように手動でチェックを行います:if (fd == AT_FDCWD) 。
ステップ 1: セットアップ
今、私たちはプログラムの実行を扱うコア関数である「do_execveat_common」に到達しました。この関数が何を行うかをコードを見つめる一時的な一歩を踏み出し、この関数が何を行うかの全体像を把握しましょう。
「do_execveat_common」の最初の主要な仕事は、「linux_binprm」と呼ばれる構造体をセットアップすることです。この構造体の全体の定義のコピーは含めませんが、以下のいくつかの重要なフィールドについて説明します:
- 「mm_struct」と「vm_area_struct」などのデータ構造は、新しいプログラムのために仮想メモリ管理を準備するために定義されています。
- 「argc」と「envc」は計算され、プログラムに渡すために保存されます。
- 「filename」と「interp」は、プログラムのファイル名とそのインタープリタをそれぞれ保存します。これらは最初は等しい値ですが、いくつかのケースでは変更されることがあります。そのようなケースの1つは、シバンを使用して解釈されるスクリプトを実行する場合です。たとえば、Pythonプログラムを実行する場合、「filename」はソースファイルを指し示しますが、「interp」はPythonインタープリタのパスを指します。
- 「buf」は、実行されるファイルの最初の256バイトで満たされた配列です。これはファイルのフォーマットを検出し、スクリプトのシバンを読み込むために使用されます。
(TIL:「binprm」はbinary programの略です。)
さて、この「buf」バッファを詳しく見てみましょう:
char buf[BINPRM_BUF_SIZE];見てわかる通り、その長さは定数 BINPRM_BUF_SIZE として定義されています。この文字列をコードベースで検索することによって、include/uapi/linux/binfmts.h 内でこの定義を見つけることができます:
/* sizeof(linux_binprm->buf) */
#define BINPRM_BUF_SIZE 256したがって、カーネルは実行ファイルの最初の256バイトをこのメモリバッファに読み込みます。
傍注: UAPIとは何ですか?
上記のコードのパスに
/uapi/が含まれていることに気付くかもしれません。なぜlinux_binprm構造体と同じファイルで長さが定義されていないのでしょうか、include/linux/binfmts.hに?UAPIは「ユーザースペースAPI」の略です。この場合、これはバッファの長さがカーネルのパブリックAPIの一部であるべきだという誰かの判断を意味します。理論的には、UAPIのすべてがユーザーランドに公開され、非UAPIのすべてがカーネルコードに対してプライベートです。
カーネルとユーザースペースのコードは元々一つの混沌とした質量で共存していました。2012年に、UAPIコードは別のディレクトリにリファクタリングされました。これは保守性を向上させる試みでした。
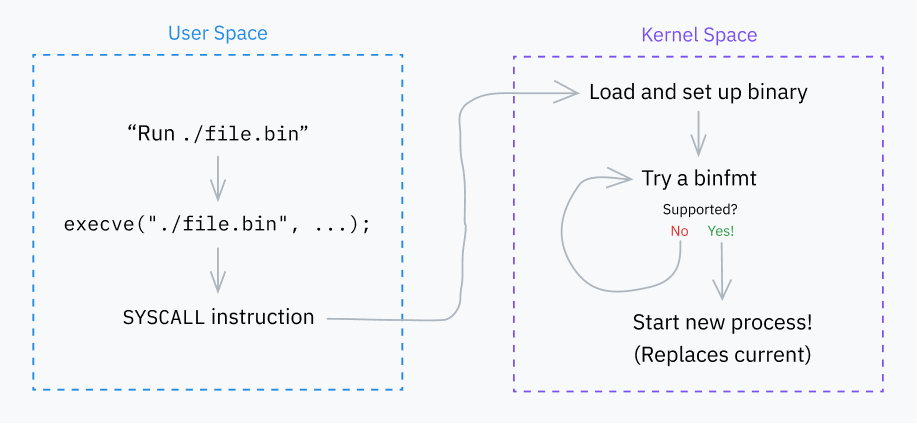
ステップ2: Binfmts
カーネルの次の主要な役割は、いくつかの「binfmt」(バイナリフォーマット)ハンドラを繰り返し処理することです。これらのハンドラは、fs/binfmt_elf.cやfs/binfmt_flat.cなどのファイルで定義されています。カーネルモジュールも、独自のbinfmtハンドラをプールに追加できます。
各ハンドラは、linux_binprm構造体を受け取り、ハンドラがプログラムのフォーマットを理解するかどうかを確認する load_binary() 関数を公開しています。
これは通常、バッファ内のマジックナンバーを探し、プログラムの開始部分をバッファからデコードしようとすること、および/またはファイル拡張子を確認することを含みます。ハンドラがそのフォーマットをサポートしている場合、プログラムを実行する準備をし、成功コードを返します。それ以外の場合、早期に終了し、エラーコードを返します。
カーネルは、成功するまで各binfmtの load_binary() 関数を試行します。これらは時々再帰的に実行されることがあります。例えば、スクリプトにインタープリタが指定されており、そのインタープリタ自体がスクリプトである場合、階層は binfmt_script > binfmt_script > binfmt_elf となる可能性があります(ここでELFはチェーンの最後にある実行可能なフォーマットです)。
フォーマットの強調: スクリプト
Linuxがサポートする多くのフォーマットの中で、binfmt_script が最初に具体的に話したいものです。
シバン(Unixのシバン)を読んだことがありますか?いくつかのスクリプトの先頭にある、インタプリタのパスを指定する行のことです。
#!/bin/bash私はいつもこれらはシェルで処理されていると思っていましたが、実はそうではありませんでした!シェバング(シェバン行)は実際にはカーネルの機能であり、スクリプトは他のすべてのプログラムと同じシスコールを使用して実行されます。コンピュータは本当にクールですね。
fs/binfmt_script.c がファイルがシェバングで始まるかどうかをチェックする方法を見てみましょう:
/* Not ours to exec if we don't start with "#!". */
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;もしファイルがシバン行で始まっている場合、binfmt ハンドラはその後、インタープリタのパスと、パスの後に空白で区切られた引数を読み取ります。新しい行またはバッファの末尾に達するまで読み取りを続けます。
ここで面白い、ちょっと奇妙な2つのことが起こっています。
まず第一に、ファイルの最初の256バイトで埋められた linux_binprm のバッファを覚えていますか?それは実行可能なフォーマットの検出に使用されますが、同じバッファが binfmt_script でシバン行を読み取るためにも使用されます。
私の研究中に、そのバッファが128バイトであると説明した記事を読みました。その記事が公開された後のある時点で、その長さは256バイトに倍増されました!なぜそうなったのか、私はLinuxソースコードで BINPRM_BUF_SIZE が定義されている行のGit blame(特定のコード行を誰が編集したかを示すログ)を確認しました。すると…
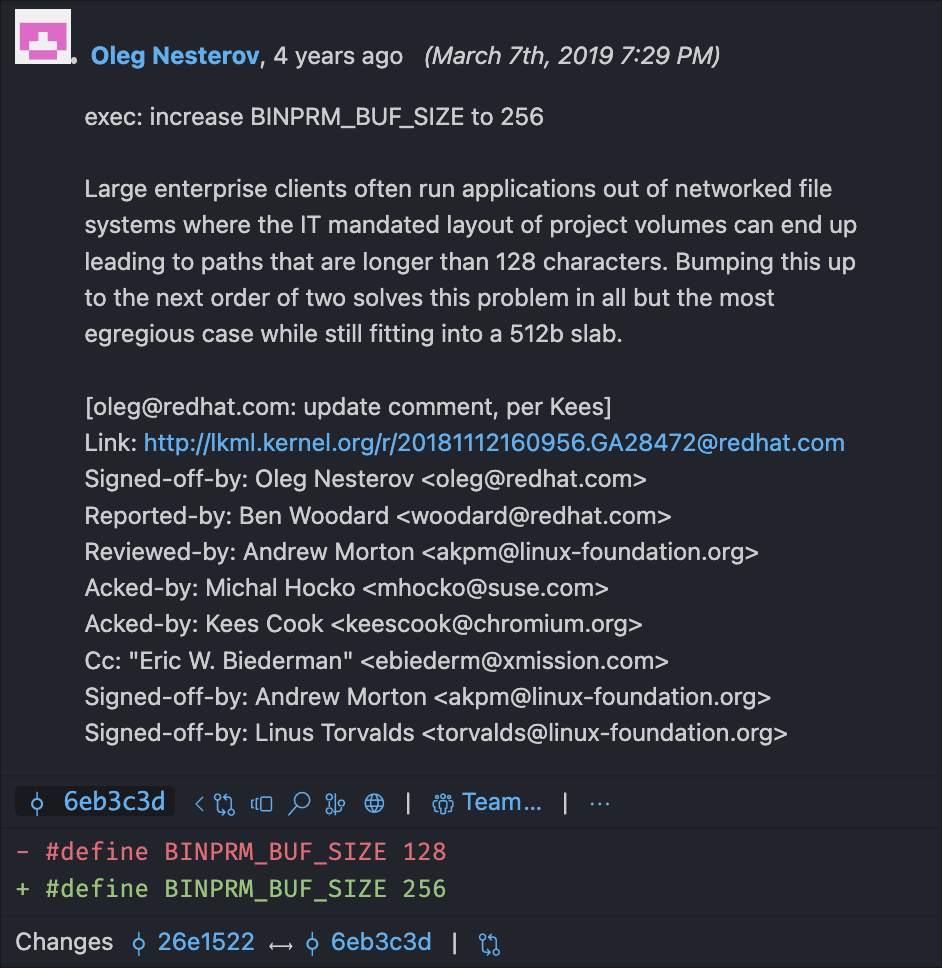
コンピュータは本当にすごいですね!
シバン行はカーネルによって処理され、ファイル全体を読み込むのではなく buf から取得されるため、常に buf の長さに切り詰められます。おそらく4年前、カーネルが128文字を超えるパスを切り詰めることにイライラした誰かが、バッファのサイズを倍にすることで切り詰めポイントを倍にした解決策を見つけました!今日、あなた自身のLinuxマシンで256文字を超えるシバン行がある場合、256文字を超える部分は完全に失われてしまいます。

これによるバグを持っていると想像してみてください。コードが壊れている原因を特定しようとすることを想像してみてください。問題がLinuxカーネルの奥深くにあることを発見すると、どのような気持ちになるでしょうか。巨大な企業で次のIT担当者が、パスの一部が謎のように消えてしまったことに気付いたときの気持ちを想像してみてください。
もうひとつの不思議なこと: argv[0]がプログラム名であることは慣例であることを覚えていますか?呼び出し元はexecシスコールに任意のargvを渡すことができ、それは無修正で渡されます。
たまたま、binfmt_scriptはargv[0]がプログラム名であると仮定している場所の一つです。常にargv[0]を削除し、次のものをargvの先頭に追加します:
- インタープリタへのパス
- インタープリタの引数
- スクリプトのファイル名
例: 引数の変更
サンプルの
execve呼び出しを見てみましょう:// Arguments: filename, argv, envp execve("./script", [ "A", "B", "C" ], []);この仮想的な
scriptファイルは、最初の行に以下のシバンを持っています:script #!/usr/bin/node --experimental-module変更された
argvが最終的にNodeインタープリターに渡されるでしょう:[ "/usr/bin/node", "--experimental-module", "./script", "B", "C" ]
argvを更新した後、ハンドラーは、linux_binprm.interpをインタープリターパス(この場合、Nodeバイナリ)に設定して、ファイルを実行する準備を完了します。最後に、プログラムの実行の準備が成功したことを示すために0を返します。
フォーマットハイライト: その他のインタープリタ
もう一つ興味深いハンドラは binfmt_misc です。これは、特別なファイルシステムを /proc/sys/fs/binfmt_misc/ にマウントすることで、ユーザーランドの設定を介して一部の限定的なフォーマットを追加できる機能を提供します。プログラムは、このディレクトリ内のファイルに 特別な形式 の書き込みを行うことで、独自のハンドラを追加できます。各設定エントリは以下を指定します:
- ファイルフォーマットの検出方法。これは、特定のオフセットでのマジックナンバーまたは探すためのファイル拡張子を指定できます。
- インタープリタの実行可能ファイルへのパス。インタープリタの引数を指定する方法はないため、それが必要な場合はラッパースクリプトが必要です。
binfmt_miscがargvを更新する方法を指定するいくつかの設定フラグ。
この binfmt_misc システムは、多くの場合、Java インストールで使用され、その設定では 0xCAFEBABE マジックバイトによってクラスファイルと、拡張子によって JAR ファイルを検出するように構成されています。私の特定のシステムでは、Python バイトコードをその .pyc 拡張子で検出し、適切なハンドラに渡すように構成されています。
これは、プログラムのインストーラが高度な特権を持つカーネルコードを書かなくても、独自のフォーマットのサポートを追加できる素晴らしい方法です。
最終的に
execシステムコールは常に次の2つのパスのいずれかに到達します:
- それは最終的に理解できる実行可能バイナリ形式に到達し、おそらくスクリプトインタプリタの複数のレイヤーを経て、そのコードを実行します。この時点で、古いコードは置き換えられています。
- … または、すべてのオプションを使い果たし、エラーコードを呼び出し元のプログラムに返し、尾を巻いて終了します。
Unixのようなシステムを使用したことがある場合、シェルスクリプトにシバン行または.sh拡張子がない場合でも、ターミナルから実行されることに気付いたかもしれません。現在非Windowsのターミナルが利用可能であれば、これを試すことができます:
$ echo "echo hello" > ./file
$ chmod +x ./file
$ ./file
hello(chmod +xはOSにファイルが実行可能であることを伝えるものです。それ以外の場合、ファイルを実行できません。)
では、なぜシェルスクリプトはシェルスクリプトとして実行されるのでしょうか? カーネルのフォーマットハンドラには、識別可能なラベルがない状態でシェルスクリプトを検出する明確な方法がないはずです!
実際、この動作はカーネルの一部ではないことが判明しました。これは、一般的にはシェルが失敗した場合の処理方法です。
ファイルをシェルを使って実行し、exec シスコールが失敗した場合、ほとんどのシェルは、ファイルをシェルスクリプトとして再試行することがあります。これは、ファイル名を最初の引数として持つシェルを実行することで行われます。Bashは通常、これを自分自身の解釈器として使用しますが、ZSHは通常、Bourneシェルとして知られるshを使用します。
この動作は、Unixシステム間でコードを移植可能にするために設計された古い標準であるPOSIXで指定されているため、一般的です。POSIXはほとんどのツールやオペレーティングシステムに厳密に従われていないものの、その多くの規約が共有されています。
もし[exec シスコール]が[ENOEXEC]エラーに相当するエラーのために失敗した場合、シェルはコマンド名を最初のオペランドとして持つシェルを呼び出した状態でのコマンドを実行します。残りの引数は新しいシェルに渡されます。実行可能ファイルがテキストファイルでない場合、シェルはこのコマンドの実行をバイパスすることがあります。この場合、エラーメッセージを書き込み、終了ステータスを126で返します。
コンピュータは本当にすごいですね!
Chapter 4: エルフ卿になる(ELF)
現在、私たちは execve をかなり理解しています。ほとんどの経路の終わりにおいて、カーネルは実行するためのマシンコードを含む最終プログラムに到達します。通常、コードにジャンプする前にセットアッププロセスが必要です。例えば、プログラムの異なる部分をメモリ内の適切な場所に読み込む必要があります。各プログラムは異なる目的のために異なる量のメモリが必要ですので、実行のためのプログラムのセットアップ方法を指定する標準ファイルフォーマットがあります。Linuxは多くのそのようなフォーマットをサポートしていますが、圧倒的に最も一般的なフォーマットは ELF (実行可能およびリンカブルフォーマット) です。

(かわいらしい絵を提供してくれた Nicky Case に感謝します。)
余談: エルフはどこにでもいますか?
Linuxでアプリやコマンドラインプログラムを実行すると、それがELFバイナリである可能性が非常に高いです。ただし、macOSでは事実上のフォーマットは Mach-O です。Mach-OはELFと同じことをすべて行いますが、構造が異なります。Windowsでは、.exeファイルは Portable Executable フォーマットを使用しますが、これもまた同じコンセプトを持つ異なるフォーマットです。
Linuxカーネルでは、ELFバイナリは binfmt_elf ハンドラによって処理され、他の多くのハンドラよりも複雑で、数千行のコードが含まれています。これはELFファイルから特定の詳細情報を解析し、それを使用してプロセスをメモリに読み込み、実行する責任を負っています。
私はいくつかのコマンドラインテクニックを使用して、binfmtハンドラを行数で並べ替えました:
$ wc -l binfmt_* | sort -nr | sed 1d
2181 binfmt_elf.c
1658 binfmt_elf_fdpic.c
944 binfmt_flat.c
836 binfmt_misc.c
158 binfmt_script.c
64 binfmt_elf_test.cファイル構造
binfmt_elfがELFファイルを実行する方法を詳しく見る前に、ファイル形式自体を見てみましょう。ELFファイルは通常、次の四つの部分から構成されています:

ELFヘッダ
すべてのELFファイルにはELFヘッダが含まれています。これはバイナリに関する基本情報を伝える非常に重要な役割を果たします:
- どのプロセッサーで実行するために設計されているか。ELFファイルにはARMやx86など、異なるプロセッサータイプのマシンコードが含まれることがあります。
- バイナリが単独で実行されることを意図しているのか、それとも他のプログラムによって「動的リンクされたライブラリ」として読み込まれることを意図しているのか。動的リンクについての詳細は後で説明します。
- 実行可能ファイルのエントリーポイント。後のセクションでは、ELFファイル内のデータをメモリにどこに読み込むかを指定します。エントリーポイントは、プロセス全体が読み込まれた後のメモリ内の最初のマシンコード命令があるメモリアドレスを指します。
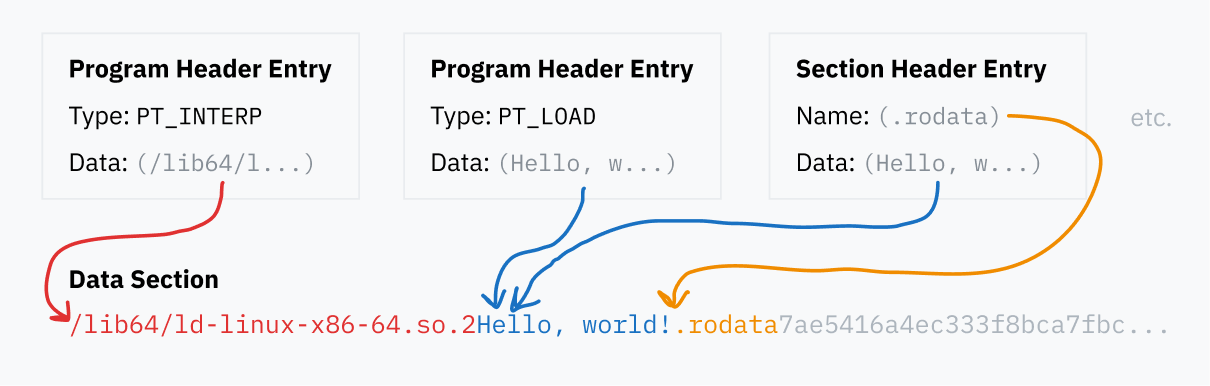
ELFヘッダは常にファイルの先頭にあります。それはプログラムヘッダテーブルとセクションヘッダの位置を指定し、これらのテーブルはさらにファイル内の他の場所に格納されたデータを指します。
プログラムヘッダーテーブル
プログラムヘッダーテーブルは、バイナリを実行時にどのようにロードして実行するかに関する具体的な詳細情報を含むエントリのシリーズです。各エントリには、どの詳細情報を指定しているかを示すタイプフィールドがあります。たとえば、PT_LOADはメモリにロードする必要があるデータを含むことを意味しますが、PT_NOTEはセグメントがメモリに必ずしもロードされる必要がない情報テキストを含むことを意味します。

各エントリは、そのデータがファイル内のどの位置にあるか、そして場合によってはそのデータをメモリにどのようにロードするかに関する情報を指定します:
- ELFファイル内のデータの位置を指します。
- データをメモリにロードする仮想メモリアドレスを指定できます。通常、セグメントがメモリにロードされる必要がない場合、これは空白のままになります。
- 2つのフィールドがデータの長さを指定します。1つはファイル内のデータの長さ、もう1つは作成されるメモリ領域の長さです。メモリ領域の長さがファイル内の長さよりも長い場合、余分なメモリはゼロで埋められます。これは、実行時に使用する静的メモリセグメントが必要なプログラムにとって有益です。これらの空のメモリセグメントは通常、BSSセグメントと呼ばれます。
- 最後に、フラグフィールドがメモリにロードされた場合に許可される操作を指定します。
PF_Rは読み取り可能、PF_Wは書き込み可能、PF_XはCPUで実行を許可するコードであることを意味します。
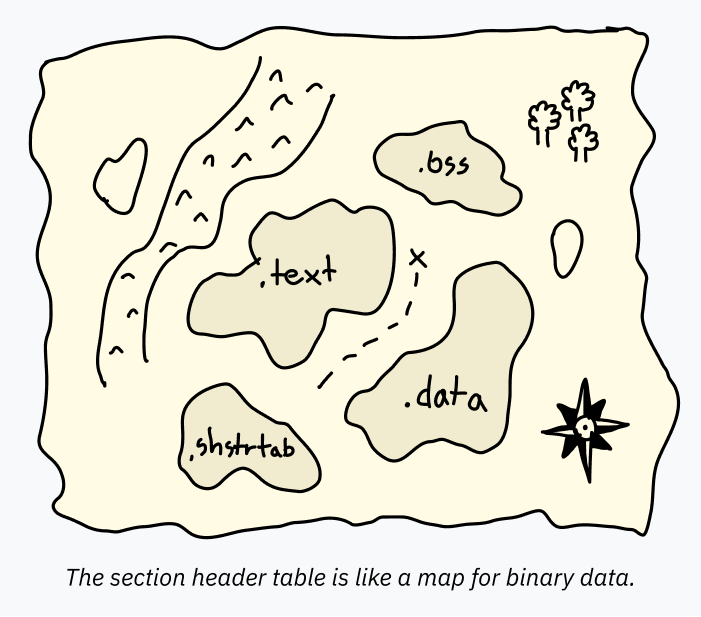
セクションヘッダーテーブル
セクションヘッダーテーブルは、セクションに関する情報を含むエントリの連続です。このセクション情報は、ELFファイル内のデータをマップのように示し、デバッガなどのプログラムがデータの異なる部分の意図された使用方法を理解しやすくします。
たとえば、プログラムヘッダーテーブルは、一緒にメモリにロードされる大量のデータを指定できます。その単一のPT_LOADブロックにはコードとグローバル変数が含まれているかもしれません!プログラムを実行するためにはそれらを別々に指定する必要はありません。CPUはエントリポイントから開始し、プログラムが要求するとき、どこでデータにアクセスするかを進めます。ただし、プログラムを分析するデバッガのようなソフトウェアは、各領域がどこで始まりどこで終わるかを正確に知る必要があります。そうでないと、テキストとして「hello」と表示されるテキストをコードとしてデコードしようとしてプログラムが失敗するかもしれません。この情報はセクションヘッダーテーブルに格納されています。
通常含まれていることが多いですが、セクションヘッダーテーブルは実際にはオプションです。ELFファイルはセクションヘッダーテーブルを完全に削除しても正常に実行でき、コードの動作を隠したい開発者は、意図的にELFバイナリからセクションヘッダーテーブルを削除または変更することがあります。デコードが難しくなるように。
各セクションには名前、タイプ、および使用方法とデコード方法を指定するフラグがあります。標準的な名前は通常、ドットで始まります。最も一般的なセクションは次のとおりです:
.text:メモリにロードされ、CPUで実行されるマシンコードです。SHT_PROGBITSタイプで、実行可能であることを示すSHF_EXECINSTRフラグと、メモリにロードされて実行されることを意味するSHF_ALLOCフラグがあります(名前に惑わされないでください、それはまだ単なるバイナリマシンコードです!「.text」と呼ばれているのに、読み取り可能な「テキスト」ではないことはいつも少し奇妙だと思っていました。).data:実行可能ファイルにハードコードされた初期化されたデータで、メモリにロードされます。たとえば、一部のテキストを含むグローバル変数がこのセクションにあるかもしれません。低レベルのコードを書く場合、これは静的変数の場所です。これもタイプSHT_PROGBITSを持ち、「プログラムの情報を含む」ことを意味するだけの「情報」セクションです。そのフラグはSHF_ALLOCとSHF_WRITEです。.bss:前述のように、初期値がゼロの割り当てられたメモリが一般的です。ELFファイルに空のバイトを大量に含めるのは無駄ですので、特別なセグメントタイプとしてBSSが使用されます。デバッグ時にBSSセグメントについて知っておくと便利です。したがって、メモリの長さを指定するセクションヘッダーテーブルエントリも存在します。これはSHT_NOBITSのタイプで、SHF_ALLOCとSHF_WRITEのフラグが設定されています。.rodata:これは.dataのようですが、読み取り専用です。非常に基本的なCプログラムが「printf(“Hello, world!”)」を実行する場合、文字列「Hello world!」は.rodataセクションに含まれ、実際の印刷コードは.textセクションに含まれます。.shstrtab:これは面白い実装の詳細です!セクション自体の名前(「.text」や「.shstrtab」など)はセクションヘッダーテーブルに直接含まれていません。代わりに、各エントリには名前を含むELFファイル内の位置へのオフセットが含まれています。これにより、セクションヘッダーテーブルの各エントリは同じサイズであるため、解析が容易になります。名前をテーブルに含める代わりに、名前データは「.shstrtab」と呼ばれる独自のセクションに保存されます。タイプはSHT_STRTABです。
データ
プログラムおよびセクションヘッダーテーブルのエントリはすべて、ELFファイル内のデータブロックを指すもので、それらをメモリにロードするか、プログラムコードの場所を指定するか、またはセクションの名前を指定するかのいずれかです。これら異なるデータの要素は、ELFファイルのデータセクションに含まれています。
リンクの簡単な説明
binfmt_elf コードに戻りましょう:カーネルはプログラムヘッダーテーブル内の2つのタイプのエントリに注意を払います。
PT_LOAD セグメントは、.text や .data セクションのようなプログラムデータがメモリにロードされる場所を指定します。カーネルはこれらのエントリをELFファイルから読み取り、データをメモリにロードしてプログラムがCPUによって実行されるようにします。
カーネルが気にするもう一つのプログラムヘッダーテーブルのエントリは PT_INTERP です。これは「動的リンクランタイム」を指定します。
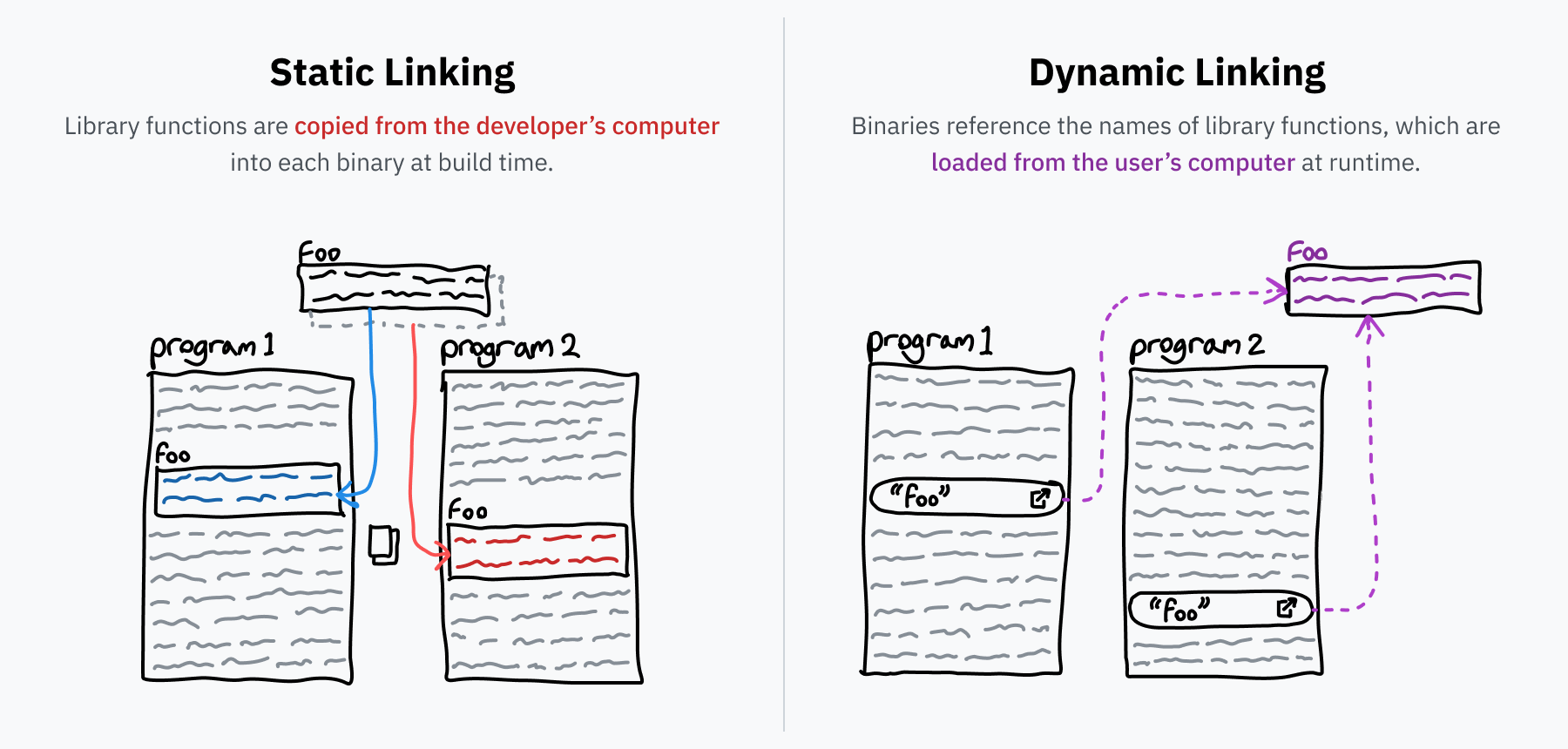
動的リンキングについて話す前に、一般的な「リンキング」について話しましょう。プログラマーは再利用可能なコードライブラリの上にプログラムを構築する傾向があります。例えば、前に話したようにlibcです。ソースコードを実行可能なバイナリに変換する際、リンカと呼ばれるプログラムがこれらの参照を解決し、ライブラリコードをバイナリにコピーします。このプロセスは「静的リンキング」と呼ばれ、外部コードが直接配布されるファイルに含まれることを意味します。
しかし、一部のライブラリは非常に一般的です。libcは例えばほとんどのプログラムで使用されています。なぜなら、これはシスコールを介してOSと対話するための標準的なインターフェースだからです。コンピューター上のすべてのプログラムに別個のlibcのコピーを含めるのはスペースの非効率的な使用ですし、ライブラリのバグがライブラリを使用する各プログラムの更新を待つ必要がある代わりに、ライブラリのバグを1か所で修正できると便利でしょう。これらの問題の解決策が動的リンキングです。
静的にリンクされたプログラムがライブラリ「bar」から「foo」という関数を必要とする場合、プログラムは「foo」の完全なコピーを含めます。しかし、動的にリンクされている場合、プログラムは「bar」ライブラリから「foo」を必要とするという参照のみを含めます。「bar」がコンピューターにインストールされていることを期待して、プログラムが実行されると、「foo」関数のマシンコードが必要に応じてメモリにロードされます。コンピューターの「bar」ライブラリのインストールが更新されると、プログラム自体を変更せずに次回プログラムが実行されると新しいコードが読み込まれます。
出回っているダイナミックリンク
Linuxでは、barのようなダイナミックリンク可能なライブラリは、通常、.so(共有オブジェクト)拡張子のファイルにパッケージ化されます。これらの.soファイルは、プログラムと同様にELFファイルです — ELFヘッダーにはファイルが実行可能なものかライブラリかを指定するフィールドが含まれていることを思い出すかもしれません。さらに、共有オブジェクトにはセクションヘッダーテーブル内に .dynsym セクションがあり、ファイルからエクスポートされたシンボルと動的にリンクできる情報が含まれています。
Windowsでは、barのようなライブラリは.dll(ダイナミックリンクライブラリ)ファイルにパッケージ化されます。macOSでは、.dylib(ダイナミックリンクライブラリ)拡張子が使用されます。macOSのアプリケーションやWindowsの.exeファイルと同様に、これらはELFファイルとはわずかに異なる形式でフォーマットされていますが、同じコンセプトと技術です。
この2つのリンクのタイプの興味深い違いの1つは、静的リンクでは、使用されているライブラリの部分のみが実行可能ファイルに含まれ、したがってメモリにロードされることです。ダイナミックリンクでは、ライブラリ全体 がメモリにロードされます。これは初めては効率が悪いように思えるかもしれませんが、実際には、現代のオペレーティングシステムがメモリにライブラリを1回ロードし、そのコードをプロセス間で共有することを可能にします。ライブラリは異なるプログラムに対して異なる状態が必要なため、コードのみ共有できますが、その節約は依然としてRAMの数十から数百メガバイトの範囲になることがあります。
実行
ELFファイルを実行しているカーネルに戻りましょう。バイナリが動的にリンクされている場合、OSはすぐにバイナリのコードにジャンプできません。なぜなら、動的にリンクされたプログラムは、必要なライブラリ関数への参照しか持っていないからです。
バイナリを実行するには、OSは必要なライブラリを特定し、それらをロードし、すべての名前付きポインタを実際のジャンプ命令で置き換え、それから実際のプログラムコードを開始する必要があります。これはELFフォーマットと深く関わる非常に複雑なコードであり、通常はカーネルの一部ではなく、スタンドアロンのプログラムです。ELFファイルは、プログラムが使用するパス(通常は /lib64/ld-linux-x86-64.so.2 のようなもの)をプログラムヘッダテーブルの PT_INTERP エントリに指定します。
ELFヘッダを読み取り、プログラムヘッダテーブルをスキャンした後、カーネルは新しいプログラムのメモリ構造を設定できます。まず、すべての PT_LOAD セグメントをメモリにロードし、プログラムの静的データ、BSS領域、およびマシンコードを埋めます。プログラムが動的にリンクされている場合、カーネルはELFインタープリタ (PT_INTERP) を実行する必要があるため、インタープリタのデータ、BSS、およびコードもメモリにロードします。
さて、カーネルはCPUの命令ポインタを設定する必要があります。実行可能ファイルが動的にリンクされている場合、カーネルはメモリ内のELFインタープリタのコードの開始地点に命令ポインタを設定します。それ以外の場合、カーネルは実行可能ファイルの開始地点に設定します。
カーネルはほとんどの準備が整い、システムコールから戻る準備ができました(まだ execve の中にいます)。カーネルはプログラムが読み取るためにargc、argv、および環境変数をスタックにプッシュします。
レジスタは今クリアされています。システムコールを処理する前に、カーネルはレジスタの現在の値をスタックに保存し、ユーザースペースに戻る際に復元されるようにします。ユーザースペースに戻る前に、カーネルはスタックのこの部分をゼロにします。
最後に、システムコールが終了し、カーネルがユーザースペースに戻ります。カーネルはレジスタを復元し、これでゼロになっています。そして、保存された命令ポインタにジャンプします。この命令ポインタは、新しいプログラム(またはELFインタープリタ)の開始地点であり、現在のプロセスが置き換えられました!
Chapter 5: コンピュータ内の翻訳家
これまで、メモリの読み書きについて話すたびに、少し曖昧な感じがしました。たとえば、ELFファイルはデータをロードするための特定のメモリアドレスを指定していますが、異なるプロセスが競合するメモリを使用しようとする問題はなぜ発生しないのでしょうか?なぜ各プロセスごとに異なるメモリ環境を持つように見えるのでしょうか?
また、ここに来るまでに具体的にどのようにしてきたのでしょうか?私たちはexecveが現在のプロセスを新しいプログラムで「置き換える」シスコールであることを理解していますが、これは複数のプロセスがどのように開始されるかを説明していません。それは確かに最初のプログラムがどのように実行されるかを説明しません — どの鶏(プロセス)が他の卵(他のプロセス)を産むのでしょうか?
私たちの旅も終盤に差し掛かっています。これらの二つの質問に答えた後、コンピュータが起動から現在使用しているソフトウェアを実行するまでのプロセスをほぼ完全に理解することになります。
メモリは仮想的
さて、メモリについてです。CPUがメモリアドレスから読み取りまたは書き込みを行うとき、実際の物理メモリ(RAM)のその場所を指しているわけではありません。むしろ、仮想メモリ空間内の場所を指しています。
CPUは、メモリ管理ユニット(MMU)と呼ばれるチップと通信します。MMUは、仮想メモリ内の場所をRAM内の場所に変換する辞書を持つ通訳のように機能します。CPUにはメモリアドレス 0xfffaf54834067fe2 から読み取る命令が与えられた場合、それを変換するようMMUに依頼します。MMUは辞書を調べ、対応する物理アドレスが 0x53a4b64a90179fe2 であることを見つけ、その番号をCPUに返します。CPUはそれからRAM内のそのアドレスから読み取ることができます。

コンピュータが起動すると、最初はメモリアクセスが直接物理RAMに行きます。起動直後、OSは翻訳辞書を作成し、CPUにMMUの使用を開始するよう指示します。
この辞書は実際にはページテーブルと呼ばれ、すべてのメモリアクセスを翻訳するこのシステムはページングと呼ばれます。ページテーブル内のエントリはページと呼ばれ、それぞれが特定の仮想メモリの一部がRAMにどのようにマップされるかを表します。これらのチャンクは常に固定サイズで、各プロセッサアーキテクチャには異なるページサイズがあります。x86-64はデフォルトで4 KiBのページサイズを持ち、つまり各ページは4,096バイトのメモリブロックのマッピングを指定します。
言い換えれば、4 KiBのページを使用する場合、アドレスの下位12ビットはMMUの変換前後で常に同じであることになります。それは、4,096バイトのページを指し示すのに必要なビット数が12だからです。
x86-64では、オペレーティングシステムが大きな2 MiBまたは4 GiBのページを有効にすることも可能で、アドレス変換の速度を向上させるかもしれませんが、メモリの断片化と浪費を増加させる可能性があります。ページサイズが大きいほど、MMUによって翻訳されるアドレスの部分が小さくなります。

ページテーブル自体はRAMに存在します。それは何百万ものエントリーを含むことができますが、各エントリーのサイズはわずか数バイトのオーダーであり、したがってページテーブルはあまり多くのスペースを占有しません。
ブート時にページングを有効にするために、カーネルは最初にRAM内にページテーブルを構築します。それから、ページテーブルの先頭の物理アドレスをページテーブルベースレジスタ(PTBR)と呼ばれるレジスタに格納します。最後に、カーネルはMMUを使用してすべてのメモリアクセスを変換するためにページングを有効にします。x86-64では、制御レジスタ3(CR3)の上位20ビットがPTBRとして機能します。ページングを有効にするために、CR0のビット31であるPG(Pagingの略)は1に設定されます。
ページングシステムの魔法は、コンピュータが稼働中にページテーブルを編集できることです。これが各プロセスが独自の隔離されたメモリスペースを持つ方法です。オペレーティングシステムが1つのプロセスから別のプロセスにコンテキストを切り替えるとき、重要なタスクの1つは仮想メモリスペースを物理メモリ内の異なる領域に再マッピングすることです。たとえば、2つのプロセスがあるとしましょう:プロセスAはそのコードとデータを(おそらくELFファイルから読み込まれているでしょう!)0x0000000000400000に持っており、プロセスBも同じアドレスからそのコードとデータにアクセスできます。これらの2つのプロセスは同じプログラムのインスタンスでさえあるかもしれません。なぜなら、彼らは実際にはそのアドレス範囲を争っていないからです!プロセスAのデータは物理メモリ内でプロセスBからは遠くにあり、プロセスに切り替えるときにカーネルによって0x0000000000400000にマップされます。
余談:呪われたELFの事実
特定の状況では、
binfmt_elfは最初のメモリページをゼロにマップする必要があります。1988年に登場した最初のELFをサポートしたOSであるUNIX System V Release 4.0(SVr4)向けに書かれた一部のプログラムは、ヌルポインタが読み取り可能であることに依存しています。そして、なぜかまだ一部のプログラムはその動作に依存しています。この振る舞いを実装したLinuxカーネルの開発者は、少し不満を抱いていたようです:
“なぜか、と聞かれるかもしれませんが? それはSVr4がページ0を読み取り専用としてマップし、一部のアプリケーションがこの動作に ‘依存’ しているからです。これらを再コンパイルする権限がないため、SVr4の振る舞いをエミュレートしています。ため息。”
ため息。
ページングによるセキュリティ
メモリ・ページングによって実現されるプロセスの隔離は、コードの使いやすさを向上させます(プロセスはメモリを使用するために他のプロセスを意識する必要はありません)。しかし、同時にセキュリティのレベルも確立します:プロセスは他のプロセスのメモリにアクセスできません。これは、この記事の冒頭で述べた元の質問の一部に対する回答の半分です:
プログラムがCPU上で直接実行され、CPUはRAMに直接アクセスできるので、なぜコードが他のプロセスまたは、もしやってしまうと、カーネルのメモリにアクセスできないのですか?
覚えていますか?それはずいぶん昔のことのように感じます…
では、カーネルメモリはどうでしょうか?まず最初に: カーネルは明らかにすべての実行中のプロセスとページテーブル自体を追跡するために十分なデータを保存する必要があります。ハードウェア割り込み、ソフトウェア割り込み、またはシステムコールがトリガーされ、CPUがカーネルモードに入るたびに、カーネルコードはそのメモリにどうやってアクセスするかを考える必要があります。
Linuxの解決策は、常に仮想メモリ空間の上半分をカーネルに割り当てることです。そのため、Linuxはハイハーフカーネルと呼ばれます。Windowsも似たような手法を採用しており、一方、macOSは… 少し 複雑 で、それについて読んでいると私の脳が耳から滲み出るかのような感じです。 ~(++)~

しかし、ユーザーランドのプロセスがカーネルメモリを読み取ったり書き込んだりできるとセキュリティ上の問題です。そのため、ページングはセキュリティの第2のレイヤーを有効にします:各ページはアクセス許可フラグを指定する必要があります。1つのフラグは領域が書き込み可能か読み取り専用かを決定します。もう1つのフラグはCPUに対して領域のメモリにアクセスできるのはカーネルモードのみ許可することを伝えます。後者のフラグは、上半分のカーネルスペース全体を保護するために使用されます。実際、ユーザースペースプログラムの仮想メモリマッピングにはカーネルメモリ全体が含まれていますが、それにアクセスする許可は持っていないだけです。

ページテーブル自体は実際にはカーネルメモリスペース内に含まれています!タイマーチップがプロセス切り替えのためにハードウェア割り込みをトリガーすると、CPUは特権レベルをカーネルモードに切り替えてLinuxカーネルコードにジャンプします。カーネルモード(Intelリング0)にあると、CPUはカーネル保護メモリ領域にアクセスできます。その後、カーネルはページテーブルに書き込むことができます(それはメモリの上半分のどこかに存在します)以前のプロセスのために仮想メモリの下半分を再マップするため。カーネルが新しいプロセスに切り替え、CPUがユーザーモードに入ると、カーネルメモリにはアクセスできなくなります。
ほぼすべてのメモリアクセスはMMUを介して行われます。割り込みディスクリプタテーブルのハンドラポインター?それらはカーネルの仮想メモリ空間を指します。
階層型ページングとその他の最適化
64ビットシステムは、メモリアドレスが64ビットであるため、64ビットの仮想メモリスペースは16 エクスビバイトものサイズです。これは非常に大きなサイズであり、今日存在するか、すぐに存在するであろうどんなコンピュータよりもはるかに大きいものです。私の知る限り、これまでのどのコンピュータにも、Blue Watersスーパーコンピュータの1.5ペタバイトを超えるRAMがありましたが、それでも16 EiBの0.01%未満です。
仮想メモリスペースの各4 KiBセクションに対してページテーブルのエントリが必要な場合、4,503,599,627,370,496個のページテーブルエントリが必要です。8バイトのページテーブルエントリを使用する場合、ページテーブルだけでも32ペビバイトのRAMが必要です。これは、コンピュータの最大RAMの世界記録よりも大きいことに気づくかもしれません。
余談: なぜ奇妙な単位を使うのか?
これは一般的ではなく、非常に見苦しいかもしれませんが、2の冪乗であるバイナリバイトサイズ単位と、10の冪乗であるメトリック単位とを明確に区別することが重要だと考えています。キロバイト(kB)は1,000バイトを意味する国際単位系(SI)の単位です。キビバイト(KiB)は、1,024バイトを意味するIEC勧告の単位です。CPUとメモリアドレスの観点からは、バイト数は通常2の冪乗であり、コンピュータは2進数システムであるためです。1,024を意味するKB(またはさらに悪い場合、kB)を使用すると、曖昧性が増す可能性があります。
可能な仮想メモリスペース全体に連続したページテーブルエントリを持つことは不可能(または非常に実用的でない)であるため、CPUアーキテクチャでは階層型ページングを実装しています。階層型ページングシステムでは、ますます細かい粒度の複数のページテーブルがあります。トップレベルエントリは大きなメモリブロックをカバーし、より小さなブロックのページテーブルを指し、ツリー構造を作成します。4 KiBまたはページサイズに関する個々のエントリは、ツリーの葉となります。
x86-64は歴史的には4レベルの階層型ページングを使用しています。このシステムでは、各ページテーブルエントリは、アドレスの一部をオフセットにして含まれるテーブルの開始位置を探し出します。この部分は最も有効ビットから始まり、エントリはこれらのビットで始まるすべてのアドレスをカバーします。エントリは次のビットコレクションでインデックスされる次のレベルのテーブルの開始位置を指します。
x86-64の4レベルのページングの設計者は、ページテーブルスペースを節約するために仮想ポインタの上位16ビットを無視することを選択しました。48ビットは128 TiBの仮想アドレススペースを提供し、これは十分大きいと見なされました。(完全な64ビットでは16 EiBになりますが、それはかなり多いです。)
最初の16ビットがスキップされているため、ページテーブルの最初のレベルをインデックスするための「最上位ビット」は、63ではなく47ビットから開始します。これはまた、この章の前半で示されていたハイハーフカーネルダイアグラムが技術的に不正確であることを意味します。カーネルスペースの開始アドレスは、64ビットよりも小さいアドレススペースの中央点として描かれるべきでした。
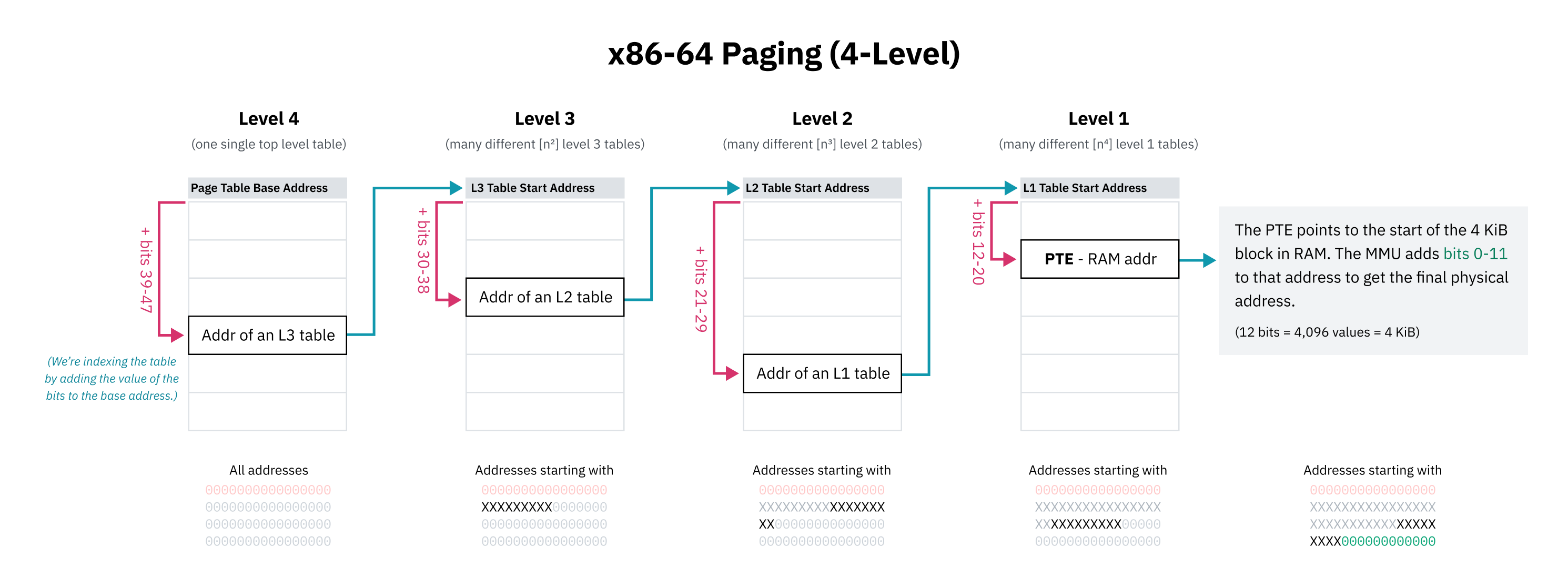
階層型ページングは、ツリーの任意のレベルで、次のエントリへのポインタをnull(0x0)にできるため、スペースの問題を解決します。これにより、ページテーブルのサブツリー全体を省略でき、仮想メモリ空間のアンマップされた領域はRAM内でスペースを占有しません。アンマップされたメモリアドレスでの検索は、CPUがツリーの上位で空のエントリを見るとすぐにエラーが発生できるため、迅速に失敗することができます。また、ページテーブルエントリには、アドレスが有効であるように見えても使用できないようにマークするために使用できる存在フラグもあります。
階層型ページングのもう一つの利点は、仮想メモリ空間の大部分を効率的に切り替える能力です。大きな仮想メモリ領域の大部分は、1つのプロセスのために物理メモリのある領域にマップされ、別のプロセスのためには別の領域にマップされることがあります。カーネルは両方のマッピングをメモリに保存し、プロセスを切り替える際には単にツリーのトップレベルのポインタを更新するだけです。仮にメモリ空間マッピング全体がエントリのフラットな配列として保存されていた場合、カーネルは多くのエントリを更新する必要があり、遅く、それにもかかわらず各プロセスのメモリマッピングを独立に追跡する必要があります。
私はx86-64が「歴史的に」4レベルのページングを使用してきたと言いましたが、最近のプロセッサは5レベルのページングを実装しています。5レベルのページングは、アドレススペースを57ビットのアドレスで128 PiBに拡張するために、別の間接レベルとさらに9つのアドレッシングビットを追加します。5レベルのページングは、Linuxを含むオペレーティングシステムで2017年以降にサポートされており、最新のWindows 10および11サーバーバージョンでもサポートされています。
余談:物理アドレススペースの制限
オペレーティングシステムが仮想アドレスのためにすべての64ビットを使用しないように、プロセッサも64ビットの物理アドレスを完全に使用しません。4レベルのページングが標準だったとき、x86-64 CPUは46ビット以上を使用しなかったため、物理アドレススペースは64 TiBに制限されていました。5レベルのページングでは、サポートが52ビットまで拡張され、4 PiBの物理アドレススペースをサポートしています。
OSのレベルでは、仮想アドレススペースが物理アドレススペースよりも大きいことが有利です。Linus Torvaldsは次のように述べています(https://www.realworldtech.com/forum/?threadid=76912&curpostid=76973):「それは少なくとも2倍、正直なところそれは限界であり、10倍以上がはるかに良いです。それを理解していない人は愚か者です。議論の余地はありません。」
スワップとデマンドページング
メモリアクセスが失敗する可能性がいくつかあります。アドレスが範囲外であるか、ページテーブルにマップされていないか、存在しないとマークされたエントリがあるかもしれません。いずれの場合でも、MMU(メモリ管理ユニット)はカーネルが問題を処理するために ページフォルト と呼ばれるハードウェア割り込みをトリガーします。
一部の場合、読み取りは実際には無効または禁止されているかもしれません。これらの場合、カーネルはおそらくプログラムを セグメンテーションフォルト エラーで終了させるでしょう。
$ ./program
Segmentation fault (core dumped)
$余談:セグフォールトのオントロジー
“Segmentation fault”(セグメンテーションフォルト)は、異なる文脈で異なる意味を持つ言葉です。メモリが許可なく読み取られると、MMU(メモリ管理ユニット)は「セグメンテーションフォルト」と呼ばれるハードウェア割り込みを発生させますが、「セグメンテーションフォルト」はまた、OSが実行中のプログラムに対して不正なメモリアクセスによりそれらを終了させるために送信できるシグナルの名前でもあります。
他の場合では、メモリアクセスは意図的に失敗することもあり、OSはメモリを埋めることができ、その後CPUに制御を戻して再試行できます。たとえば、OSはディスク上のファイルを実際にRAMにロードせずに仮想メモリにマップし、アドレスが要求され、ページフォルトが発生したときに物理メモリにロードします。これをデマンドページングと呼びます。

一方、これにより、mmapなどのシスコールが存在することができます。これらのシスコールはディスクから仮想メモリにファイル全体を遅延マップするものです。LLaMa.cppというFacebookのリークした言語モデルのランタイムがわかる場合、最近Justine Tunneyはすべてのローディングロジックをmmapに使うように最適化しました。もし彼女を以前聞いたことがない場合は、彼女の作品をチェックしてみてください!Cosmopolitan LibcとAPEは本当にクールで、この記事を楽しんでいるなら興味があるかもしれません。
明らかに多くの ドラマ が Justineのこの変更に関与しているようです。無作為なインターネットユーザーから叫ばれないように、これを指摘しておきます。私はそのドラマのほとんどを読んでいないことを告白しなければなりませんが、私が言ったことがJustineの作品がクールだということはまだ本当です。
プログラムとそのライブラリを実行するとき、カーネルは実際には何もメモリにロードしません。カーネルはファイルのmmapを作成するだけです。CPUがコードを実行しようとすると、ページはすぐにフォルトが発生し、カーネルはページを実際のメモリブロックで置き換えます。
デマンドページングはまた、おそらく「スワッピング」または「ページング」として知っているテクニックを可能にします。オペレーティングシステムはメモリページをディスクに書き込んで物理メモリから削除し、仮想メモリに存在フラグを0に設定したままにします。その仮想メモリが読み取られると、OSはメモリをディスクからRAMに復元し、存在フラグを1に戻します。OSはディスクの読み取りと書き込みが遅いため、オペレーティングシステムは効率的なページ置換アルゴリズムを使用してスワップをできるだけ少なくするように努力します。
興味深いハックの1つは、ファイルの物理ストレージ内の場所を格納するためにページテーブルの物理メモリポインタを使用することです。MMUは存在フラグが負の場合すぐにページフォルトが発生するため、無効なメモリアドレスであることは関係ありません。これはすべてのケースで実用的ではありませんが、考えるだけでも面白いアイデアです。
Chapter 6: フォークと牛について話そう(Forks and Cows)
最後の質問:どのようにしてここに到達したのか?最初のプロセスはどこから来たのか?
この記事はほぼ完成しています。最終ストレッチに入っています。ホームランを打つ寸前です。より良い未来に向かって進んでいます。そして、あなたがCPUアーキテクチャについての15,000ワードの記事を読んでいないときに、草を触るか何をしているのか、その他さまざまなひどい慣用句です。
もしexecveが現在のプロセスを置き換えて新しいプログラムを起動するのであれば、新しいプログラムを別々のプロセスで起動するにはどうすればいいのでしょうか?これは、コンピュータ上で複数のことをしたい場合に非常に重要な能力です。アプリをダブルクリックして起動すると、そのアプリは別に開かれ、以前のプログラムは引き続き実行されます。
答えは別のシステムコールです:fork、すべてのマルチプロセッシングに基本的なシステムコールです。forkはかなりシンプルで、実際には現在のプロセスとそのメモリをクローンし、保存された命令ポインタをそのままにして、両方のプロセスが通常通りに進行することを可能にします。介入しない場合、プログラムはお互いに独立して実行され、すべての計算が倍になります。
新しく実行されるプロセスは「子」と呼ばれ、forkを呼び出した最初のプロセスは「親」と呼ばれます。プロセスは複数回forkを呼び出すことができ、それにより複数の子プロセスを持つことができます。各子プロセスにはプロセスID(PID)が割り当てられ、1から始まります。
同じコードを無知に倍にすることはかなり無駄なので、forkは親と子で異なる値を返します。親では、新しい子プロセスのPIDを返し、子では0を返します。これにより、新しいプロセスで異なる作業を行うことができるため、forkingが実際に役立ちます。
pid_t pid = fork();
// Code continues from this point as usual, but now across
// two "identical" processes.
//
// Identical... except for the PID returned from fork!
//
// This is the only indicator to either program that they
// are not one of a kind.
if (pid == 0) {
// We're in the child.
// Do some computation and feed results to the parent!
} else {
// We're in the parent.
// Probably continue whatever we were doing before.
}プロセスのフォークは少し頭を巻かせることがあります。これ以降、あなたがそれを理解したと仮定します。理解していない場合は、この見た目がひどいウェブサイト をチェックして、かなり良い説明を見てください。
とにかく、Unixプログラムは新しいプログラムを起動する際に fork を呼び出し、その後すぐに子プロセスで execve を実行します。これは fork-exec パターン と呼ばれています。プログラムを実行すると、コンピューターは次のようなコードを実行します:
pid_t pid = fork();
if (pid == 0) {
// Immediately replace the child process with the new program.
execve(...);
}
// Since we got here, the process didn't get replaced. We're in the parent!
// Helpfully, we also now have the PID of the new child process in the PID
// variable, if we ever need to kill it.
// Parent program continues here...ムーーーー!
プロセスのメモリを複製して、すぐに異なるプログラムを読み込む際にそれをすべて破棄することが少し非効率的に聞こえるかもしれません。幸い、私たちはMMU(メモリ管理ユニット)を持っています。物理メモリ内でデータを複製するのが遅い部分であり、ページテーブルを複製しないだけです。したがって、RAMを複製しないのです。古いプロセスのページテーブルのコピーを新しいプロセスのために作成し、マッピングを同じ基盤の物理メモリを指すように保ちます。
しかし、子プロセスは親から独立して隔離されているべきです!子プロセスが親のメモリに書き込むこと、またその逆が許容されるわけではありません!
ここで登場するのがCOW(コピー・オン・ライト)ページです。COWページを使用すると、メモリに書き込もうとしない限り、両方のプロセスは同じ物理アドレスから読み取ります。どちらかがメモリに書き込もうとすると、そのページがRAM内でコピーされます。COWページにより、両方のプロセスがメモリの隔離を持つことができ、メモリ全体をクローンする前に前払い費用がかからないのです。これがfork-execパターンが効率的である理由です。新しいバイナリを読み込む前に古いプロセスのメモリが書き込まれないため、メモリのコピーが必要ありません。
COWは、多くの楽しいことと同様に、ページングのハックとハードウェア割り込み処理で実装されています。forkが親をクローンすると、両方のプロセスのすべてのページを読み取り専用としてフラグ付けします。プログラムがメモリに書き込もうとすると、メモリが読み取り専用であるため、書き込みに失敗します。これにより、セグフォルト(ハードウェア割り込みの種類)がトリガーされ、カーネルによって処理されます。カーネルはメモリを複製し、ページを書き込み可能に更新し、割り込みから復帰して書き込みを再試行します。
A: ノック、ノック!
B: 誰ですか?
A: 割り込み牛。
B: 割り込み牛は —
A: モーーー!
はじめに(創世記1:1ではないよ)
コンピュータ上のすべてのプロセスは、親プログラムによってフォークされ、実行されましたが、1つだけ例外があります:initプロセスです。initプロセスは、カーネルによって直接手動で設定されます。これは最初に実行されるユーザーランドプログラムであり、シャットダウン時には最後に終了します。
クールな瞬間のブラックスクリーンを見たいですか? macOSまたはLinuxを使用している場合は、作業を保存し、ターミナルを開いてinitプロセス(PID 1)を終了してみてください:
$ sudo kill 1著者の注意: initプロセスに関する知識は、残念ながらmacOSやLinuxなどのUnix系システムにのみ適用されます。これから学ぶことのほとんどは、非常に異なるカーネルアーキテクチャを持つWindowsの理解には適用されません。
execveセクションと同様に、これについては明示的に言及しています — NTカーネルについて別の記事を書くこともできますが、今はそれを控えています。(今のところ)
initプロセスは、オペレーティングシステムを構成するすべてのプログラムとサービスを起動する責任を負っています。それらの多くは、さらに自分自身のサービスとプログラムを起動します。
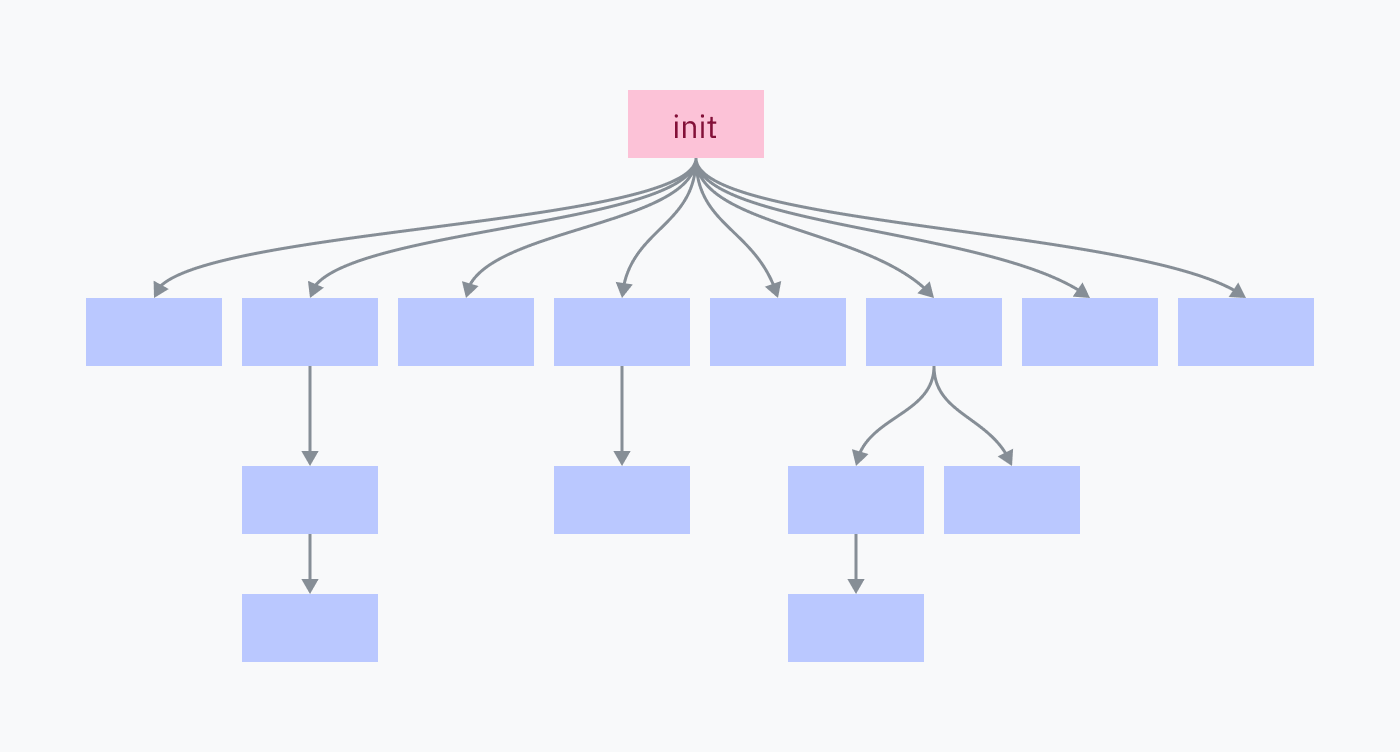
initプロセスを終了させると、そのすべての子プロセスとその子プロセスが終了し、オペレーティングシステム環境がシャットダウンします。
カーネルに戻る
第3章でLinuxカーネルコードを見て楽しんだので、もう少し詳しく見てみましょう!今回は、カーネルがinitプロセスを起動する方法を見てみます。
コンピュータは次のようなシーケンスで起動します:
マザーボードには、接続されたディスクを検索し、ブートローダと呼ばれるプログラムを探す小さなソフトウェアがバンドルされています。それはブートローダを選び、そのマシンコードをRAMに読み込み、実行します。
OSが実行中ではないことに注意してください。OSカーネルがinitプロセスを起動するまで、マルチプロセッシングやシスコールは実際には存在しません。初期化前の状態では、プログラムを”実行”するとは、戻りの期待なしにRAM内のそのマシンコードに直接ジャンプすることを意味します。
ブートローダは、カーネルを見つけ、RAMに読み込み、実行する責任があります。一部のブートローダ、例えばGRUBのようなものは、設定可能で、複数のオペレーティングシステムから選択できます。BootXとWindows Boot Managerは、それぞれmacOSとWindowsの組み込みのブートローダです。
カーネルは今実行中であり、割り込みハンドラの設定、ドライバの読み込み、初期メモリマッピングの作成など、大規模な初期化タスクを開始します。最終的に、カーネルは特権レベルをユーザーモードに切り替え、initプログラムを起動します。
ついにオペレーティングシステムのユーザーランドにいます!initプログラムはinitスクリプトの実行、サービスの起動、シェル/UIのようなプログラムの実行を開始します。
Linuxの初期化
Linuxでは、ステップ3(カーネルの初期化の大部分)は、init/main.c内のstart_kernel関数で実行されます。この関数は、さまざまな他の初期化関数への200行以上の呼び出しで構成されているため、全体をこの記事に含めることはしませんが、スキャンをお勧めします! start_kernelの最後で、arch_call_rest_initという名前の関数が呼び出されます:
/* Do the rest non-__init'ed, we're now alive */
arch_call_rest_init();非__init’edとは何ですか?
start_kernel関数はasmlinkage __visible void __init __no_sanitize_address start_kernel(void)と定義されています。__visible、__init、および__no_sanitize_addressなどの奇妙なキーワードは、Linuxカーネルで関数にさまざまなコードや動作を追加するために使用されるCプリプロセッサマクロです。この場合、
__initは、ブートプロセスが完了すると関数とそのデータをメモリから解放するようカーネルに指示するマクロであり、単にスペースを節約するためです。では、どのように機能するのでしょうか?詳細に立ち入らずに説明すると、Linuxカーネル自体がELFファイルとしてパッケージ化されています。
__initマクロは__section(".init.text")に展開され、これは通常の.textセクションの代わりにコードを.init.textセクションに配置するためのコンパイラディレクティブです。他のマクロもデータや定数を特別なイニシャライズセクションに配置できるようにします。たとえば、__initdataは__section(".init.data")に展開されます。
arch_call_rest_init は単なるラッパー関数です:
void __init __weak arch_call_rest_init(void)
{
rest_init();
}コメントには「残りの部分は __init ではないものを実行してください」と書かれています。なぜなら rest_init は __init マクロで定義されていないからです。これは、初期化メモリのクリーンアップ時に解放されないことを意味します:
noinline void __ref rest_init(void)
{...}rest_initは今や初期化プロセス用のスレッドを作成します:
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
pid = user_mode_thread(kernel_init, NULL, CLONE_FS);user_mode_thread に渡される kernel_init パラメータは、いくつかの初期化タスクを完了し、その後有効な初期化プログラムを検索して実行する関数です。この手順はいくつかの基本的なセットアップタスクから始まります。ほとんどの部分ではこれらをスキップしますが、free_initmem が呼び出される箇所は例外です。ここで、カーネルは私たちの .init セクションを解放します!
free_initmem();今、カーネルは適切な初期化プログラムを実行できるようになりました:
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (CONFIG_DEFAULT_INIT[0] != '\0') {
ret = run_init_process(CONFIG_DEFAULT_INIT);
if (ret)
pr_err("Default init %s failed (error %d)\n",
CONFIG_DEFAULT_INIT, ret);
else
return 0;
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");Linuxでは、initプログラムはほぼ常に/sbin/initに配置されているか、シンボリックリンクされています。一般的なinitプログラムには systemd(非常に優れたウェブサイトを持っています)、OpenRC、および runit が含まれます。kernel_init は他に見つからない場合にはデフォルトで /bin/sh を使用します — そして、/bin/sh が見つからない場合、何かが非常に問題があることを意味します。
MacOSにもinitプログラムがあります!それはlaunchdと呼ばれ、/sbin/launchdに配置されています。カーネルでないことに対して叱られたい場合、ターミナルでそれを実行してみてください。
ここから、ブートプロセスのステップ4に進みます:initプロセスはユーザーランドで実行され、フォーク-エグゼクパターンを使用してさまざまなプログラムを起動し始めます。
フォークメモリマッピング
Linuxカーネルがプロセスをフォークする際にメモリの下半分をどのようにリマップするのかについて興味を持ち、少し調査しました。kernel/fork.c は、プロセスのフォークに関するほとんどのコードが含まれているようです。このファイルの冒頭部分は、私に正しい場所を示す役に立ちました:
/*
* 'fork.c' contains the help-routines for the 'fork' system call
* (see also entry.S and others).
* Fork is rather simple, once you get the hang of it, but the memory
* management can be a bitch. See 'mm/memory.c': 'copy_page_range()'
*/この copy_page_range 関数は、メモリマッピングに関する情報を取得し、ページテーブルをコピーするようです。この関数が呼び出す関数を大まかに見てみると、ここでページを読み取り専用に設定してCOW(Copy-On-Write)ページにする場所でもあるようです。これを行うかどうかは、is_cow_mapping という関数を呼び出すことで判断されます。
is_cow_mapping は、include/linux/mm.h で定義されており、メモリマッピングに関連する flags が、そのメモリが書き込み可能でプロセス間で共有されていないことを示す場合に true を返します。共有メモリは共有を前提としているため、COW する必要はありません。少し理解しづらいビットマスキングに感嘆しましょう:
static inline bool is_cow_mapping(vm_flags_t flags)
{
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}kernel/fork.cのkernel/fork.cに戻りましょう。copy_page_rangeを検索すると、dup_mmap関数から1つの呼び出しを見つけることができます。そして、dup_mmapはさらにdup_mmから呼び出され、dup_mmはcopy_mmから呼び出されます。最終的には、巨大なcopy_process関数から呼び出されます! copy_processはフォーク機能の中心であり、ある意味でUnixシステムがプログラムを実行する中心点です - 常に最初のプロセスのために起動時に作成されたテンプレートをコピーして編集します。
まとめ…
それでは、プログラムはどのように実行されるのでしょうか?
最も低いレベルでは、プロセッサは単純です。メモリ内のポインタを持ち、指示を連続して実行します。指示が別の場所にジャンプするように指示されるまで、そのまま実行を続けます。
ジャンプ命令の他にも、ハードウェアおよびソフトウェアの割り込みが、実行のシーケンスを中断し、予め設定された場所にジャンプしてからどこにジャンプするかを選択できます。プロセッサコアは複数のプログラムを同時に実行できませんが、タイマーを使用して割り込みを繰り返しトリガーし、カーネルコードに異なるコードポインタ間で切り替えることでシミュレートできます。
プログラムは、自分たちが統一された孤立した単位として実行されているかのようにだまされています。ユーザーモードではシステムリソースへの直接アクセスが防止され、ページングを使用してメモリスペースが分離され、システムコールは真の実行コンテキストについてあまり知識を必要とせずに一般的なI/Oアクセスを許可するように設計されています。システムコールは、CPUにカーネルコードを実行するように要求する命令であり、その位置はカーネルが起動時に設定します。
しかし… プログラムはどのように実行されるのでしょうか?
コンピュータが起動すると、カーネルがinitプロセスを起動します。これは、その機械語が多くの具体的なシステムの詳細を心配する必要がない、抽象度の高い最初のプログラムです。initプログラムは、コンピュータのグラフィカルな環境をレンダリングし、他のソフトウェアを起動する責任があります。
プログラムを起動するために、initプロセスはforkシスコールを使用して自身を複製します。このクローンは効率的です。すべてのメモリページはCOW(Copy On Write)であり、メモリを物理RAM内でコピーする必要はありません。Linuxでは、これはcopy_process関数が動作しています。
両方のプロセスは、自身がフォークされたプロセスであるかどうかをチェックします。フォークされたプロセスである場合、新しいプログラムを起動するためにexecシスコールを使用してカーネルに現在のプロセスを新しいプログラムで置き換えるように要求します。
新しいプログラムはおそらくELFファイルであり、カーネルはプログラムをどのようにロードし、新しい仮想メモリマッピング内にコードとデータを配置するかの情報を解析します。カーネルは、プログラムが動的にリンクされている場合にはELFインタープリタを準備するかもしれません。
カーネルはプログラムの仮想メモリマッピングをロードし、プログラムが実行中であるということは、実際にはCPUの命令ポインタを新しいプログラムの仮想メモリ内のコードの開始位置に設定することを意味します。
Chapter 7: 最後に
おめでとうございます!私たちは今、CPUに「あなた」をしっかりと配置しました。楽しんでいただけたら嬉しいです。
最後にもう一度強調してお送りいたしますが、今回得たすべての知識は実際に活用できます。次にコンピュータが複数のアプリを実行していると考えるとき、タイマーチップやハードウェア割り込みを思い浮かべていただきたいです。また、何か新しいプログラムをファンシーなプログラミング言語で書いてリンカーエラーが発生したとき、そのリンカーが何をしようとしているのか考えていただければ幸いです。
この記事に関する質問(または訂正)がある場合は、lexi@hackclub.com までメールしていただくか、GitHubで問題を提出するかPRを作成してください:GitHub。

… でも待ってください、もっとあります!
ボーナス: Cの概念を翻訳
もし低レベルプログラミングを自分で行ったことがあるなら、おそらくスタックとヒープが何かを知っていて、mallocを使用したことがあるかもしれません。しかし、それらがどのように実装されているかについてはあまり考えたことがないかもしれません!
まず第一に、スレッドのスタックは、仮想メモリの高い位置にマップされた固定のメモリ量です。ほとんどのアーキテクチャでは、スタックポインタはスタックメモリの一番上から始まり、増加するにつれて下方に移動します。物理メモリは、マップされたスタックスペース全体に対して最初から割り当てられるわけではありません。代わりに、デマンドページングが使用され、スタックのフレームが到達するたびにメモリが遅延して割り当てられます。
mallocのようなヒープの割り当て関数がシステムコールではないことは驚かれるかもしれません。代わりに、ヒープメモリ管理はlibcの実装によって提供されています! malloc、freeなどは複雑な手順であり、libcはメモリマッピングの詳細を自身で追跡します。ユーザーランドのヒープアロケータは、mmap(ファイル以外のものもマップできる)およびsbrkを含むシステムコールを使用しています。
ボーナス: 余談
これらをまとめて置く場所がどこにも見当たりませんでしたが、面白いと思ったので、以下に示します。
おそらくほとんどのLinuxユーザーは、ページテーブルがカーネル内でどのように表現されているかを想像する時間がほとんどないほど十分に興味深い人生を送っているでしょう。
ハードウェア割り込みの別の視覚化:

一部のシステムコールは、カーネル空間にジャンプする代わりにvDSOと呼ばれる技術を使用しています。これについては話す時間がありませんでしたが、非常に興味深いですし、読むこと をお勧めします 。
そして最後に、Unixの批判に対処します。実行に関する多くの内容が非常にUnix固有ですので、macOSまたはLinuxユーザーの場合は問題ありませんが、Windowsがプログラムを実行したりシステムコールを処理する方法にはあまり近づけません。ただし、CPUアーキテクチャに関する部分はすべて同じです。将来的には、Windowsの世界をカバーする記事を書くことができればと思います。
謝辞
この記事を執筆する際に、GPT-3.5とGPT-4と多くの対話をしました。彼らは多くの情報が役に立たないばかりか、私に嘘をつくことが多かったですが、時折問題を解決するのに非常に役立ちました。LLM(言語モデル)の支援は、その制限を認識し、彼らが言うことに極めて懐疑的である場合にはプラスになることがあります。とは言え、彼らは文章を書くのが非常に下手です。決して彼らに文章を書かせないでください。
さらに重要なこととして、私を校正し、励まし、アイデアを出すのに助けてくれたすべての人々に感謝します。特に、Ani、B、Ben、Caleb、Kara、polypixeldev、Pradyun、Spencer、Nicky(第4章で素晴らしいエルフを描いてくれた方)、そして私の素敵な両親に感謝します。
もしもあなたが10代で、コンピュータが好きで、Hack Club Slackにまだ参加していないなら、今すぐ参加すべきです。私は自分の考えや進捗状況を共有する素晴らしいコミュニティがなければ、この記事を書かなかったでしょう。もしも10代でない場合、寄付をして、私たちが素晴らしいことを続けられるようにしてください。
この記事の中の平凡なアートはすべてFigmaで描かれました。編集にはObsidianを使用し、時折Valeをリントツールとして使用しました。この記事のMarkdownソースはGitHubで利用可能であり、将来的な細かい指摘に対して公開されています。また、すべてのアートはFigmaコミュニティページで公開されています。